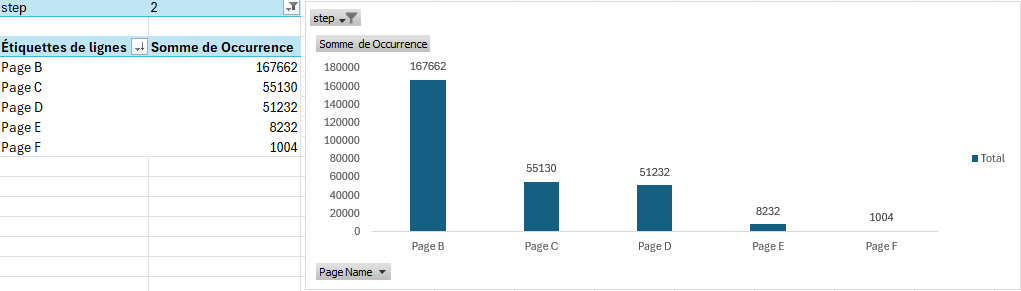
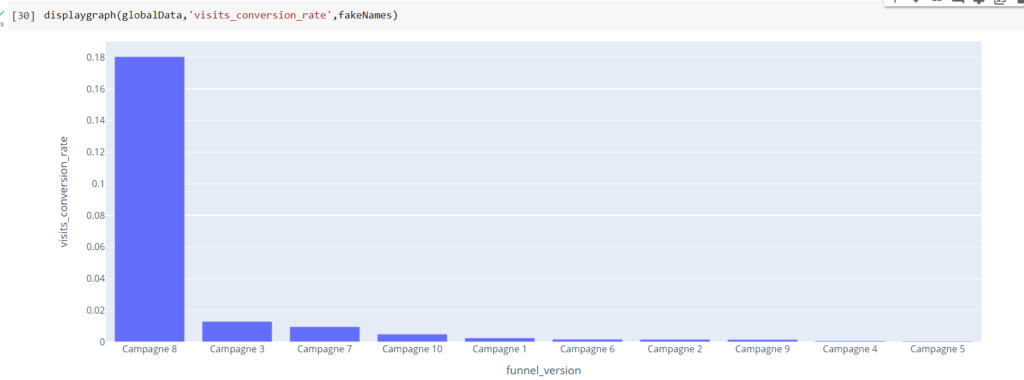
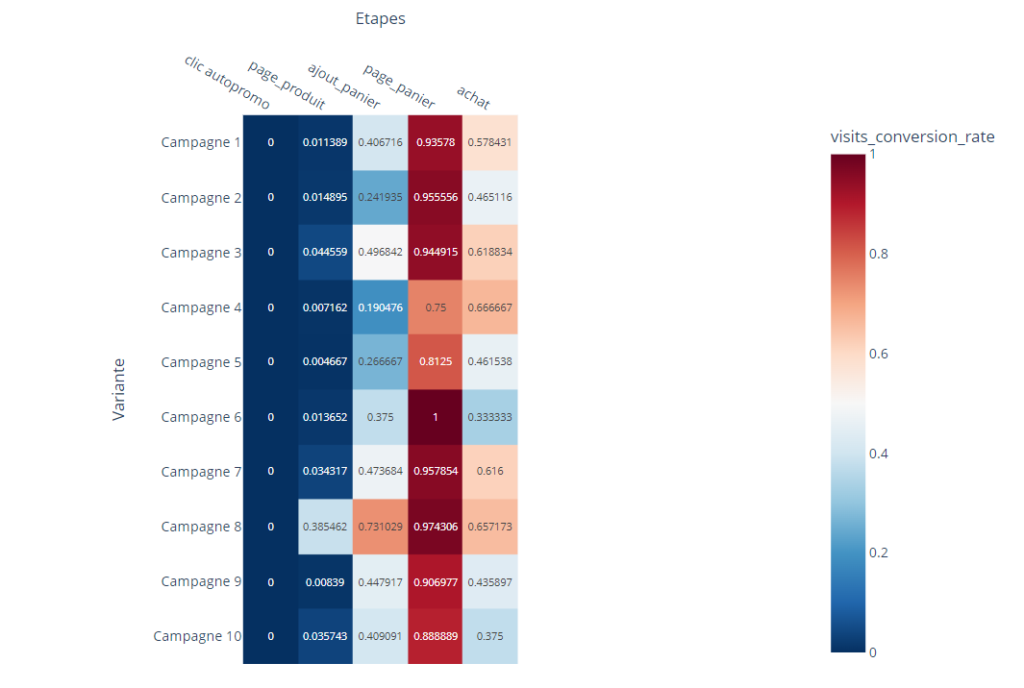
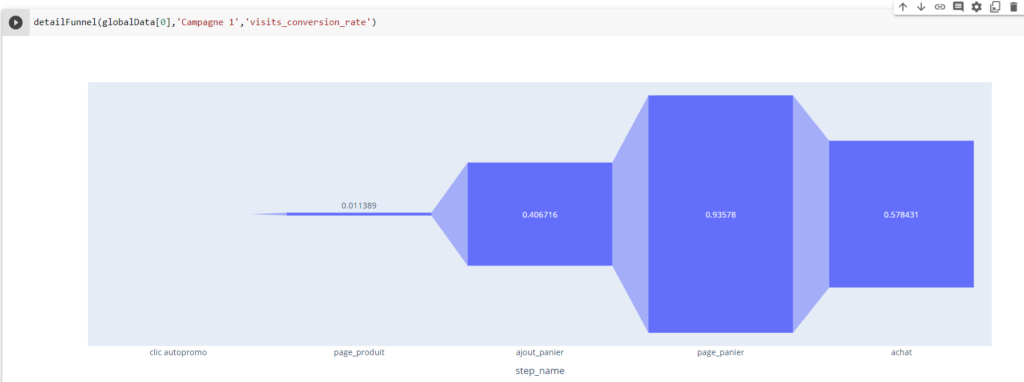
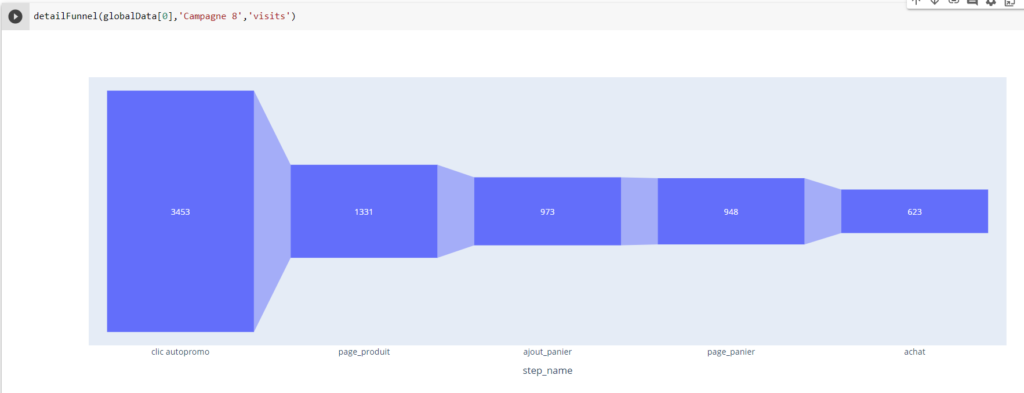
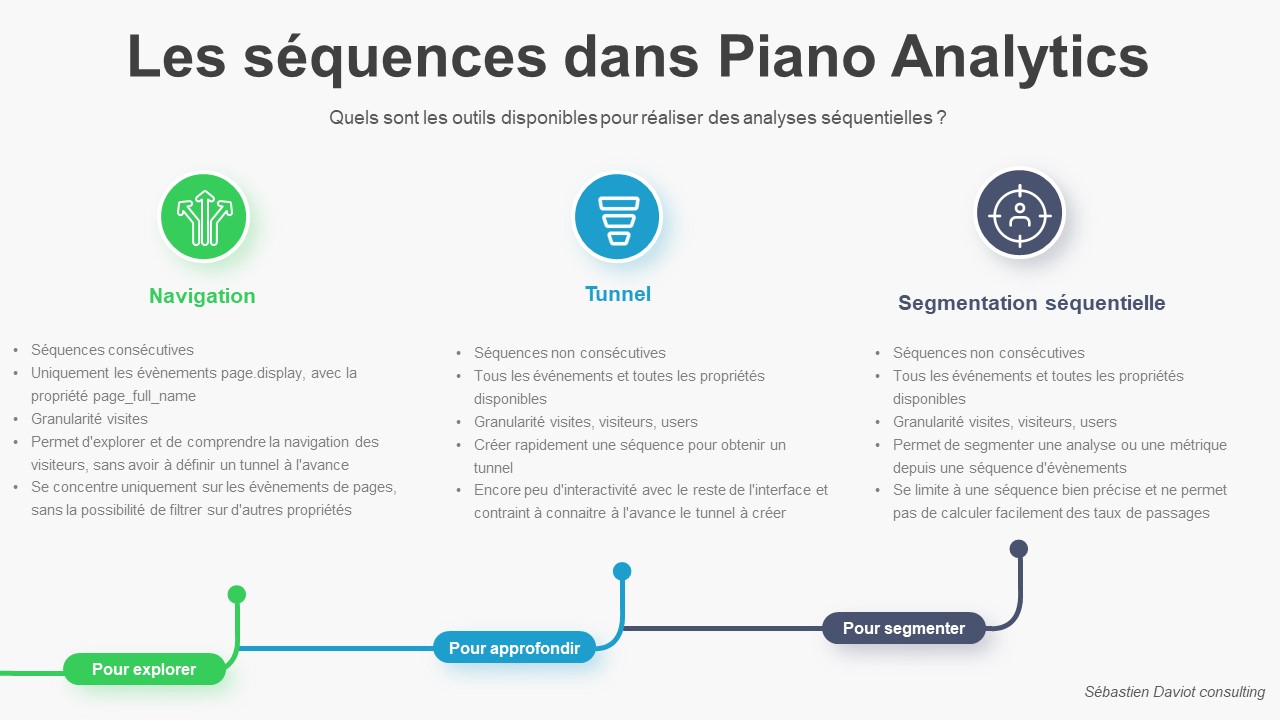
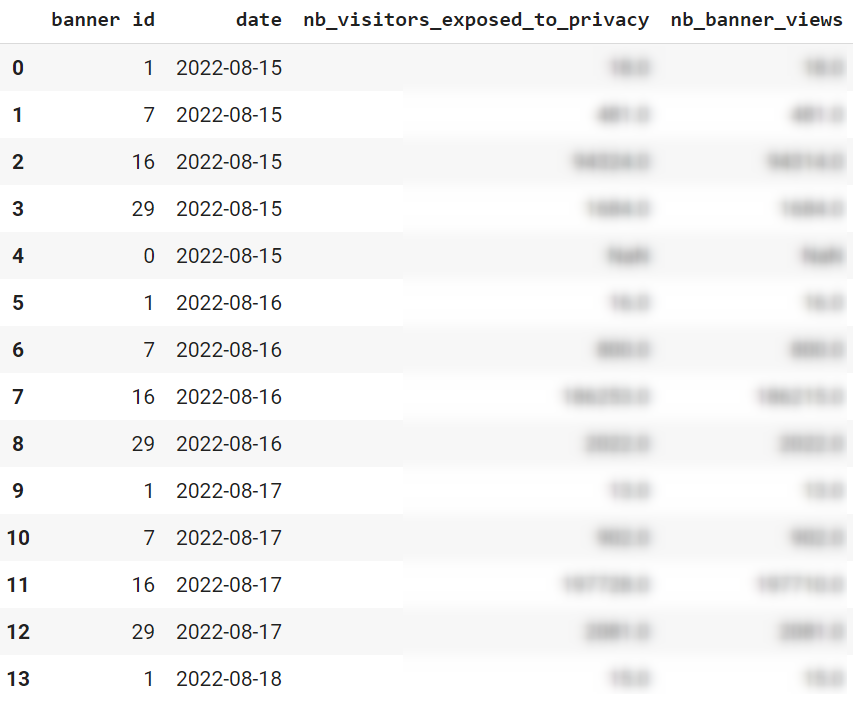
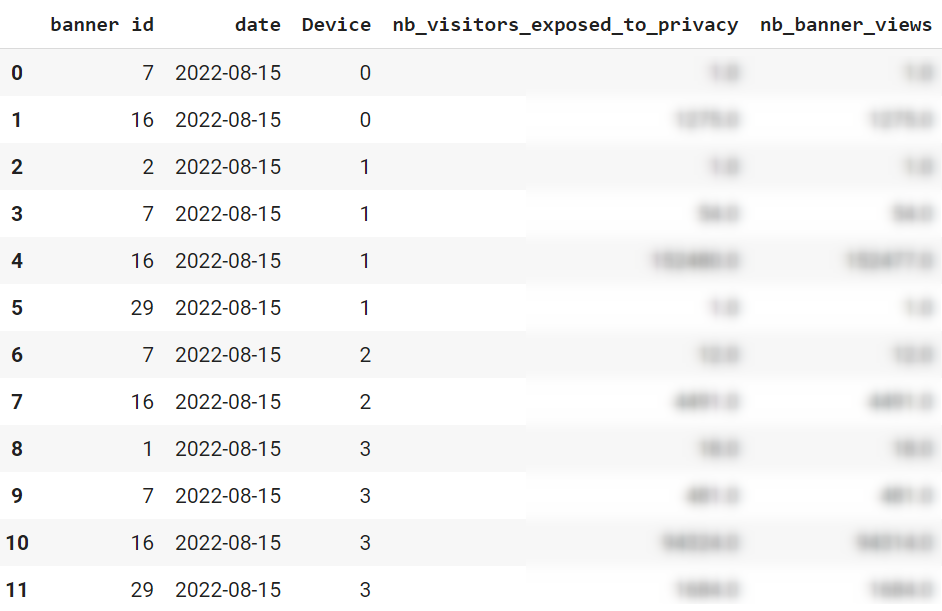
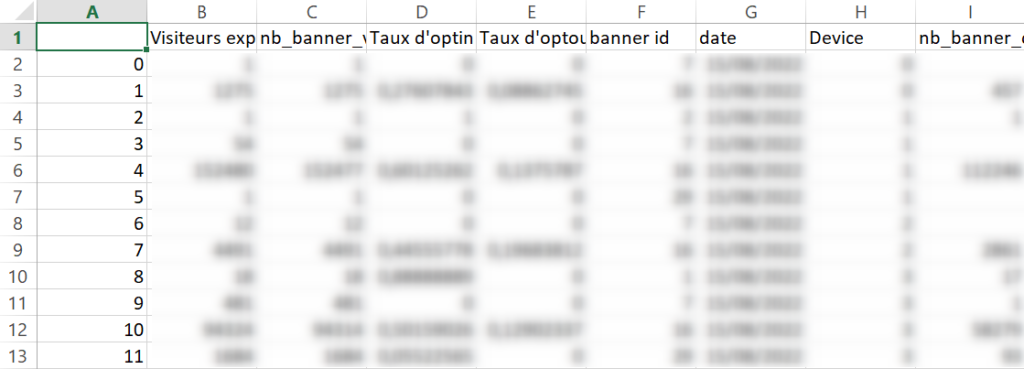
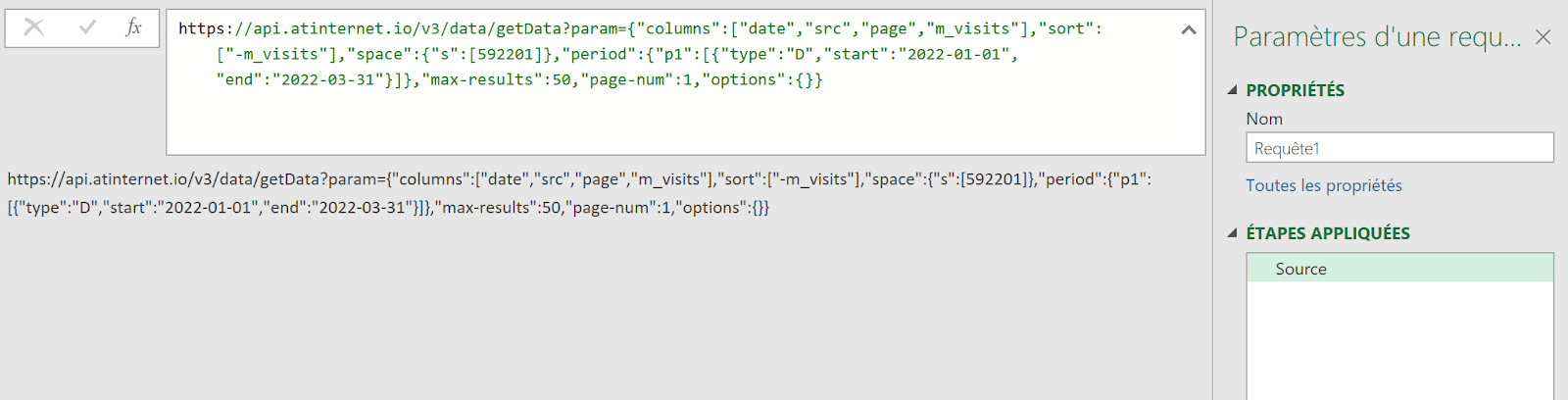
Introduction
Quand on m’a expliqué pour la première fois le concept de Measurements dans Piano Analytics, je vous avoue ne pas avoir été subjugué : de ma compréhension, il s’agissait de pousser une valeur journalière d’une donnée externe pour faire apparaître une courbe dans un board, mais sans possibilité de croisement avec les données Piano… on en revenait donc à faire un appel API externe en standalone dans un graphique, rien d’extraordinaire.
Maaaaais, en creusant davantage le sujet dernièrement, je me suis rendu compte que la fonctionnalité était bien plus sophistiquée qu’en première lecture :
- Choix des agrégations à effectuer
- Possibilité de pousser de la donnée textuelle
- Création de métriques calculées mixant des données de measurements et des données Analytics classiques
- Réexploitation de propriétés de son data model (standards ou custom) pour affiner les mesures poussées et mieux les intégrer dans ses données Analytics
- Création de visualisations mixant données de measurements et données analytics
- Possibilité de filtrer et segmenter (sous certaines conditions) ces valeurs
- Fonctionnalités IA disponibles sur les données issues de measurements
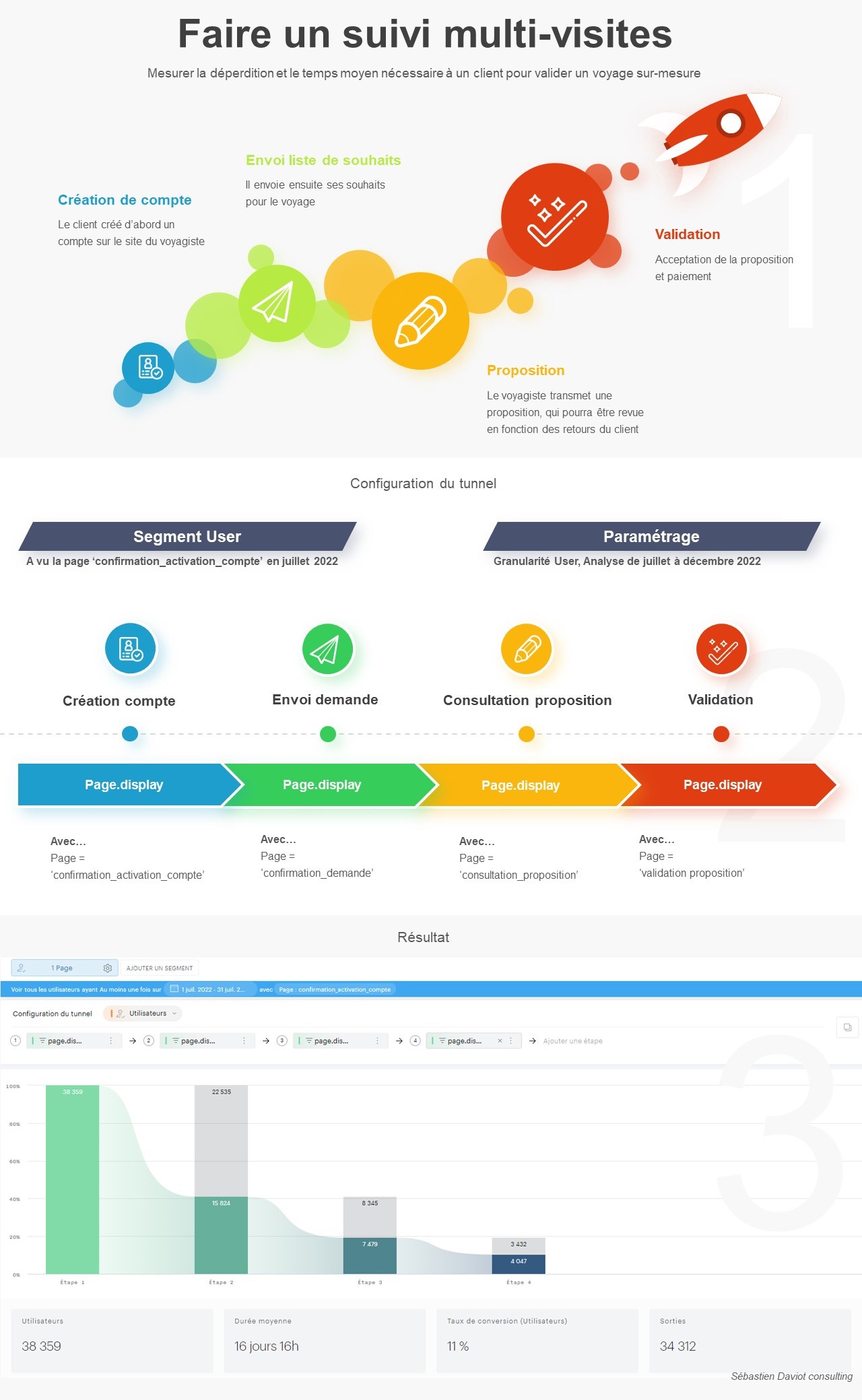
Je suis donc maintenant clairement beaucoup plus positif vis-à-vis de cette fonctionnalité, qui peut s’appliquer dans de nombreux use cases, et je souhaite vous présenter à travers cet article un cas permettant d’exploiter l’ensemble des possibilités offertes par les measurements : la création d’un board contenant les données quantitatives et qualitatives des avis de votre application sur le Google Play Store et l’Apple Store :
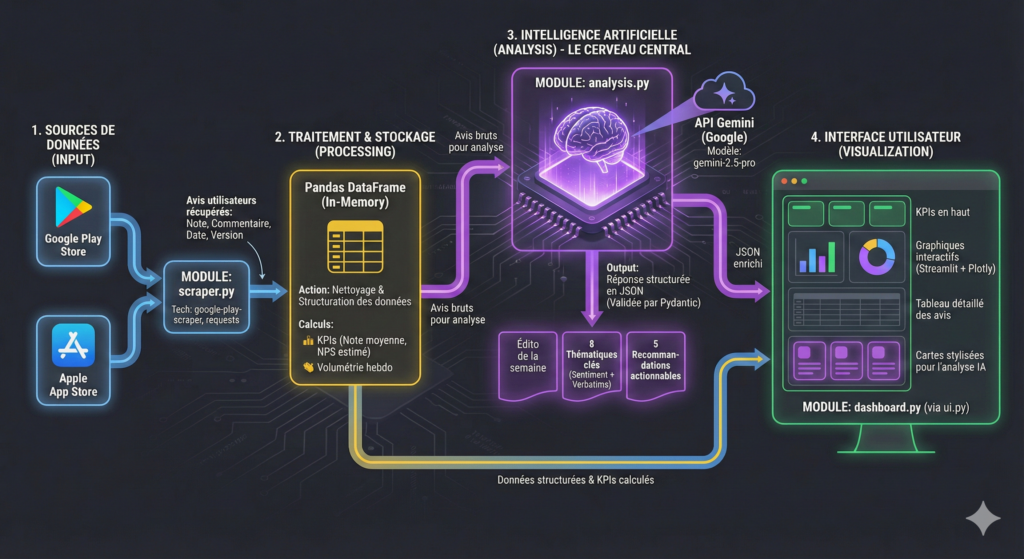
Je rassure tout de suite les moins techniques d’entre vous, il va surtout s’agir ici de comprendre le fonctionnement des measurements dans Piano et pas de comprendre à la virgule près le code qui se cache derrière : j’ai donc tenté de le faire le plus accessible possible.
Je rassure également les plus techniques d’entre vous, la dernière partie de l’article sera dédiée à la compréhension de l’ensemble du pipeline Python utilisé pour enrichir via l’IA les données des stores et injecter cette donnée dans Piano.
Faire sa première configuration des measurements dans Piano
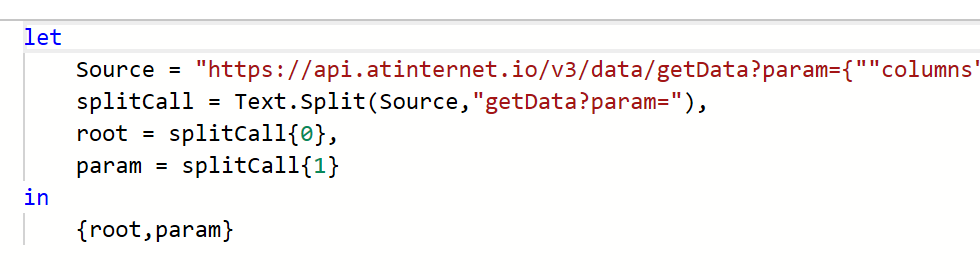
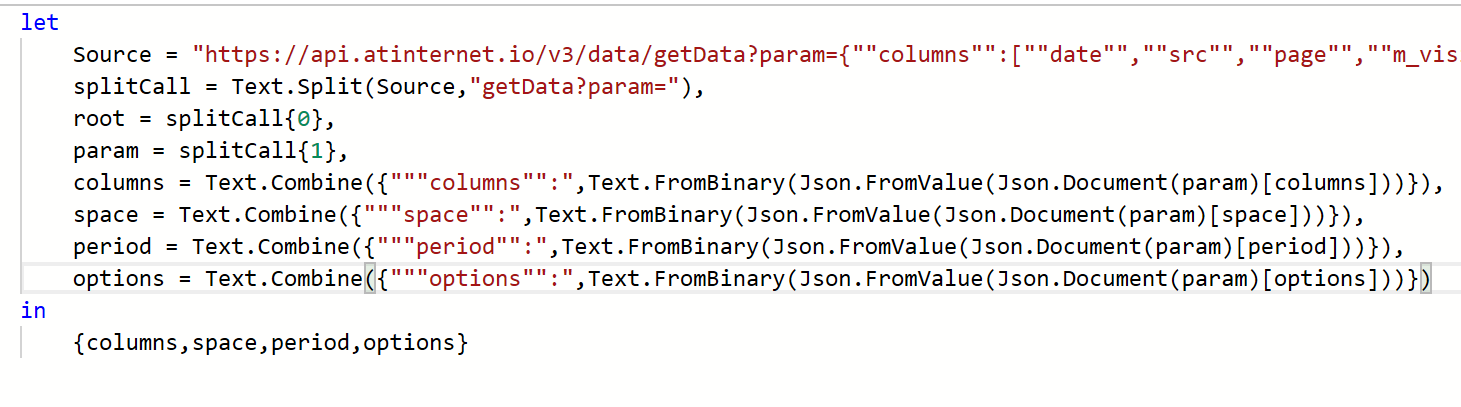
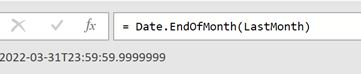
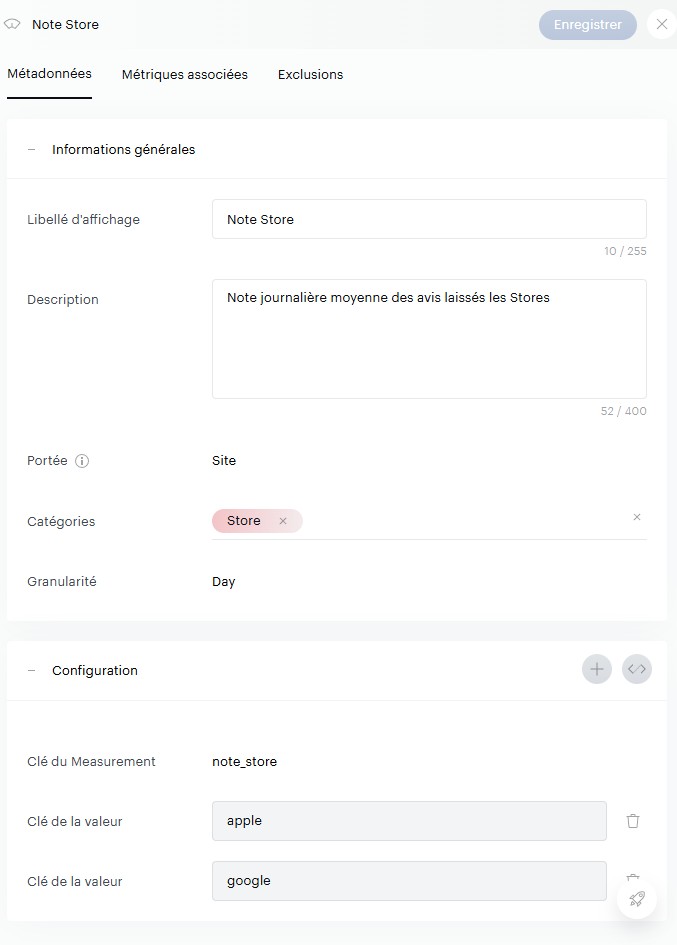
Avant même de se plonger dans les données récupérées des stores, nous allons déjà essayer de comprendre comment injecter des premières mesures . Notre premier objectif est simple : réussir à pousser les notes sur 5 de notre application sur les 2 stores pour une journée donnée.
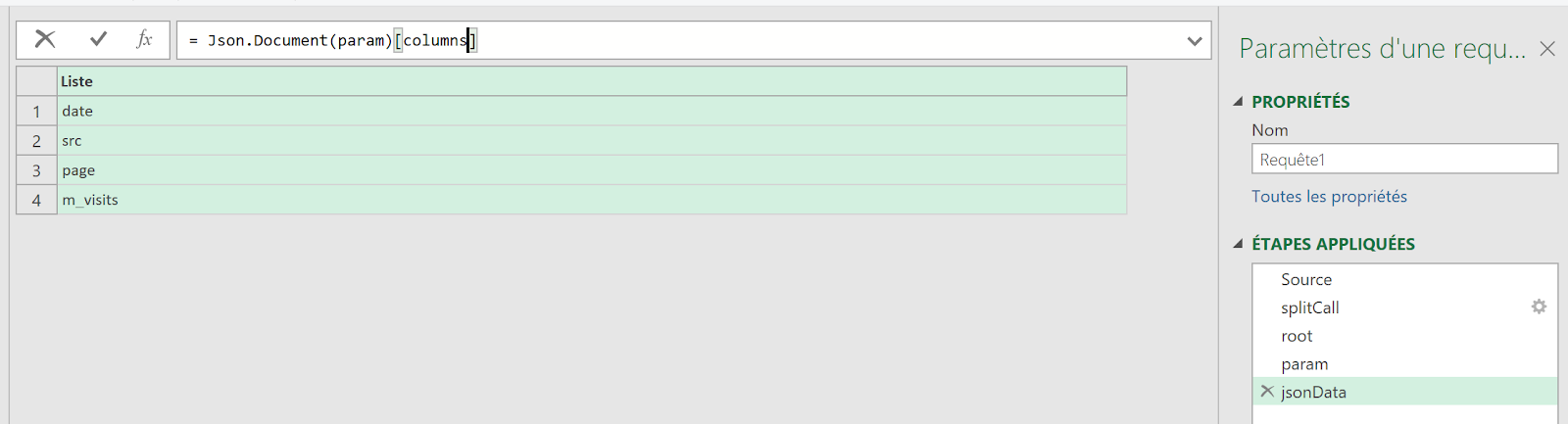
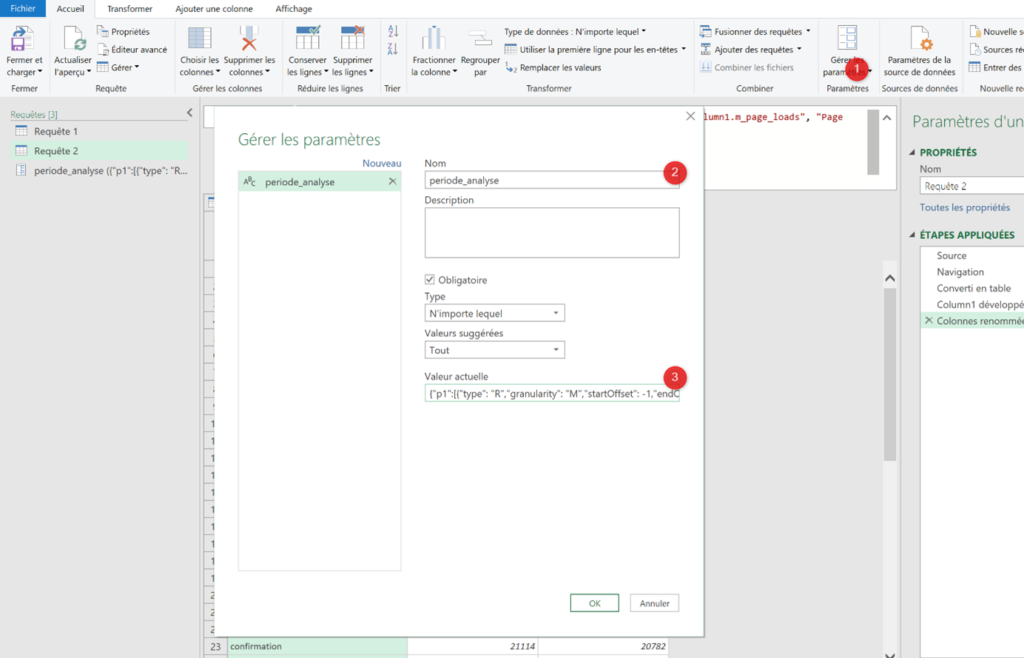
Pour ça, on va se rendre dans la rubrique Measurements de votre data model .
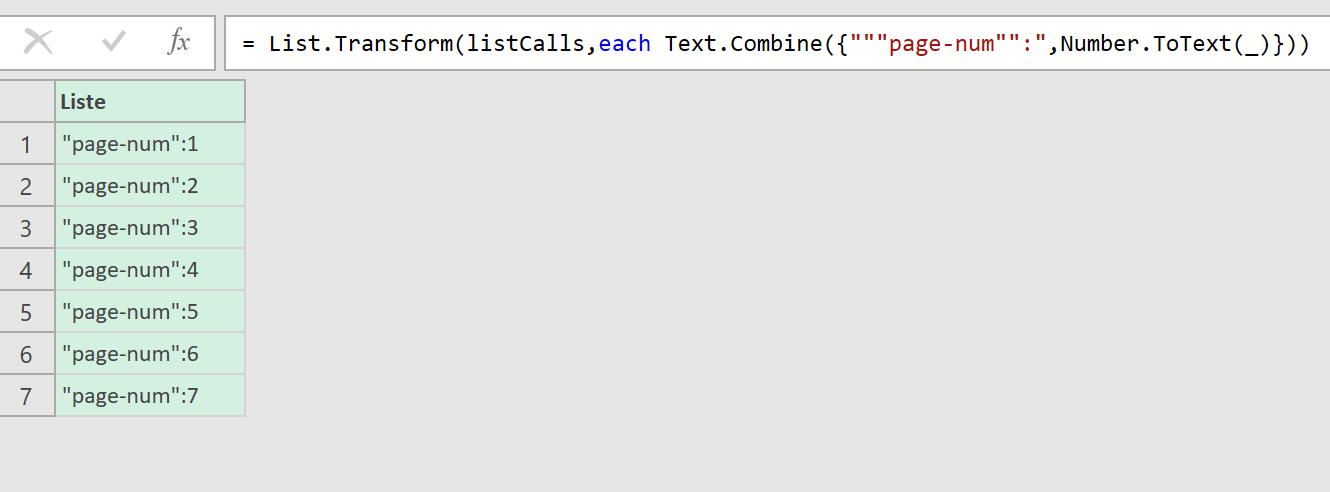
Vous allez cliquer sur le « + » et configurer votre première mesure. Pour cela, il faut bien comprendre l’imbrication des éléments :
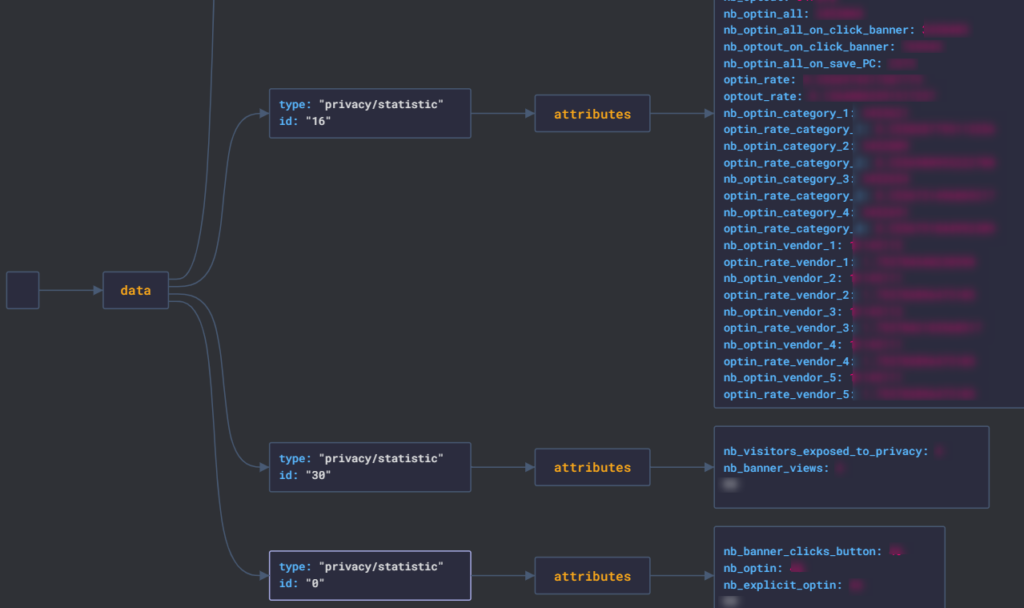
- Votre Measurement est votre réceptacle global, il va pouvoir contenir plusieurs données injectables. Dans notre cas ici, nous lui donnons un nom « commun » aux 2 stores :
Note_store. - Vous devez ensuite indiquer des « clés », et il s’agit ici des valeurs finales que vous allez pousser vers Piano. Dans notre cas ici, nous avons 2 informations à pousser, une note sur 5 par store, nous en créons donc 2 :
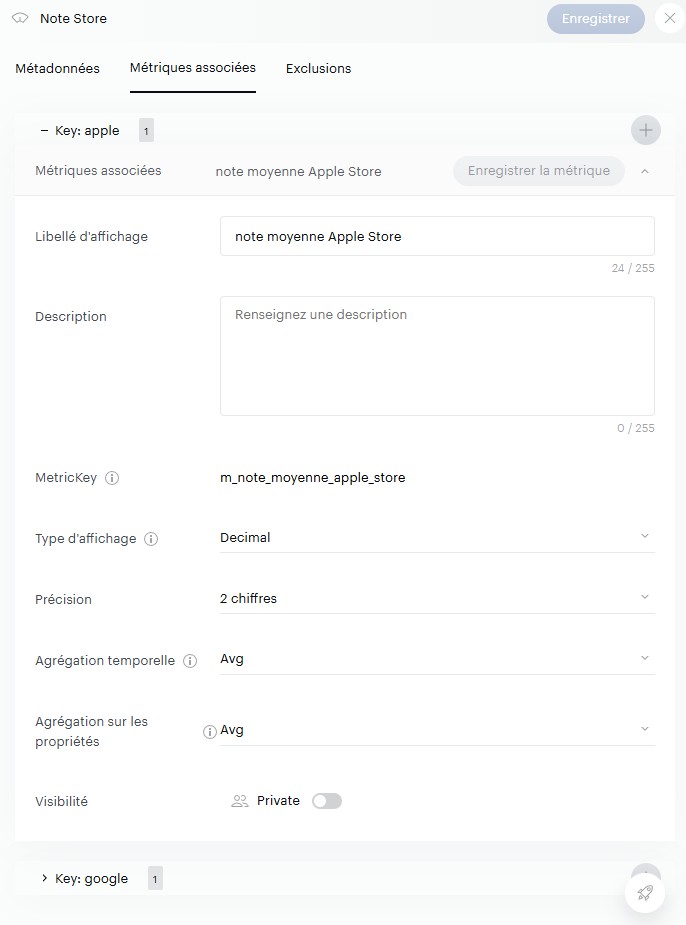
appleetgoogle. - Finalement, vous devez configurer des « métriques », qui décrivent la manière dont sera restituée votre clé. Est-ce un nombre ou du texte ? Doit-on sommer ou faire une moyenne des valeurs journalières quand on sélectionne 1 semaine de données dans le calendrier Piano ?
À noter que vous pouvez définir plusieurs métriques pour une clé donnée, afin de faire par exemple une agrégation via une moyenne dans un cas, et une autre via une somme dans un autre .
Dans notre cas, nous ne ferons qu’une seule agrégation par clé, basée sur des chiffres décimaux avec une agrégation sur la moyenne.
Une fois que vous avez compris cela, il ne vous reste plus qu’à déterminer :
- Si le measurement s’applique à toute votre organisation ou bien à un seul site
- À quelle granularité vous souhaitez pousser cette donnée : heure, jour, mois…
Dans mon cas, voici ma configuration :
La configuration des mesures, c’est fait, on va maintenant s’assurer que vous ayez bien une clé API disponible pour la suite. Pour cela, allez dans votre profil et créez une clé API si vous n’en avez pas. Important : notez bien votre access key et votre secret key quelque part .
Injecter ses premiers measurements
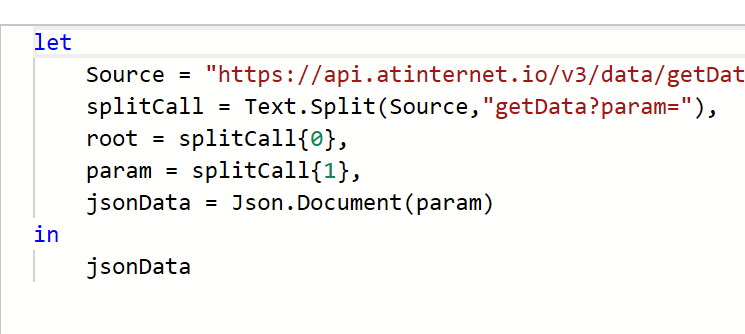
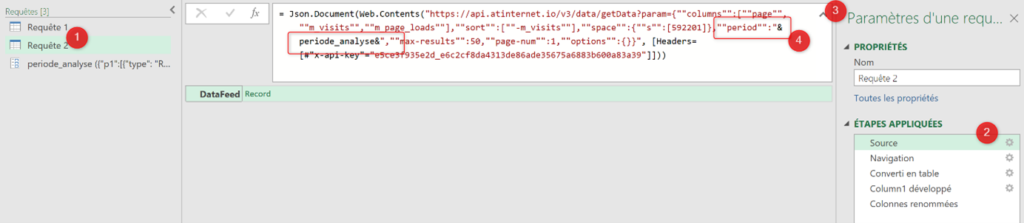
On va maintenant pouvoir lancer notre appel API de test, que nous allons faire en Python.
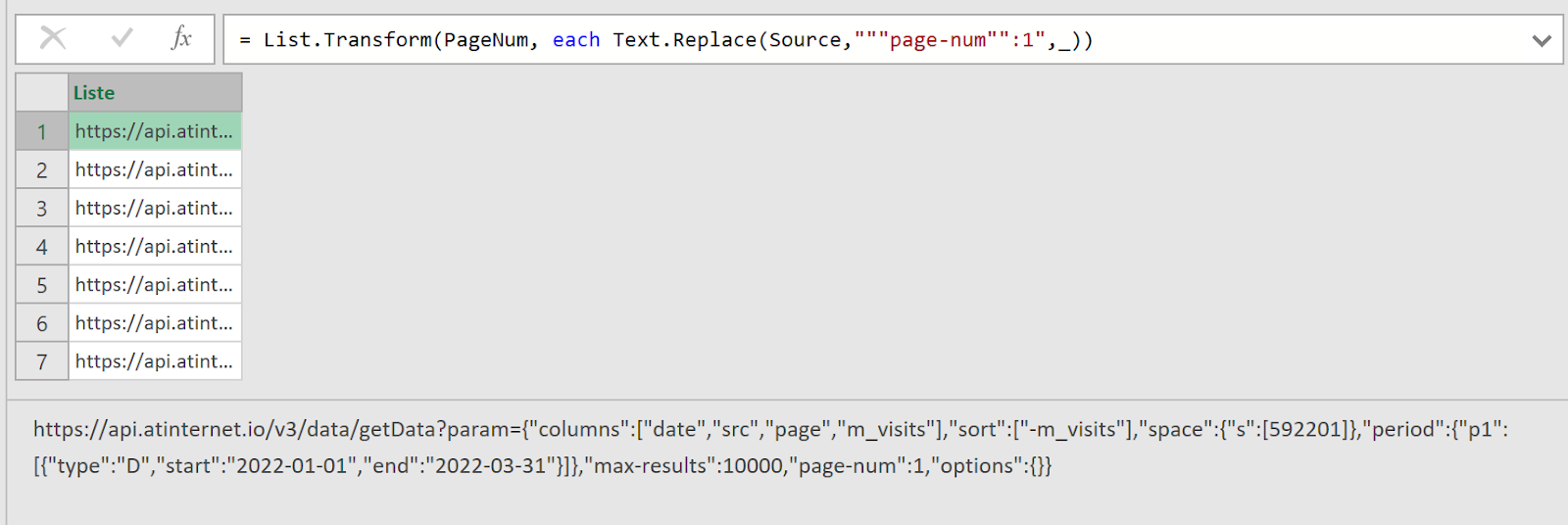
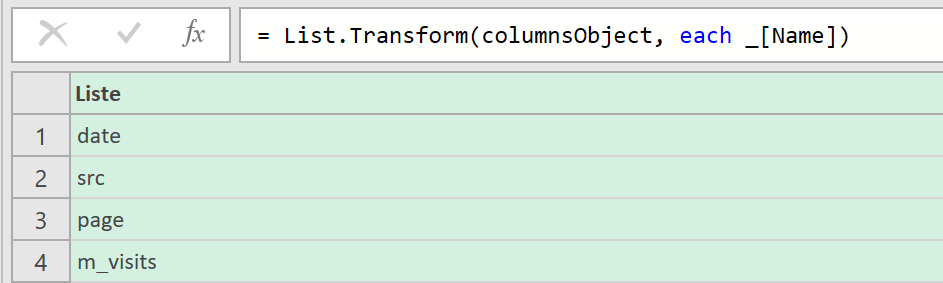
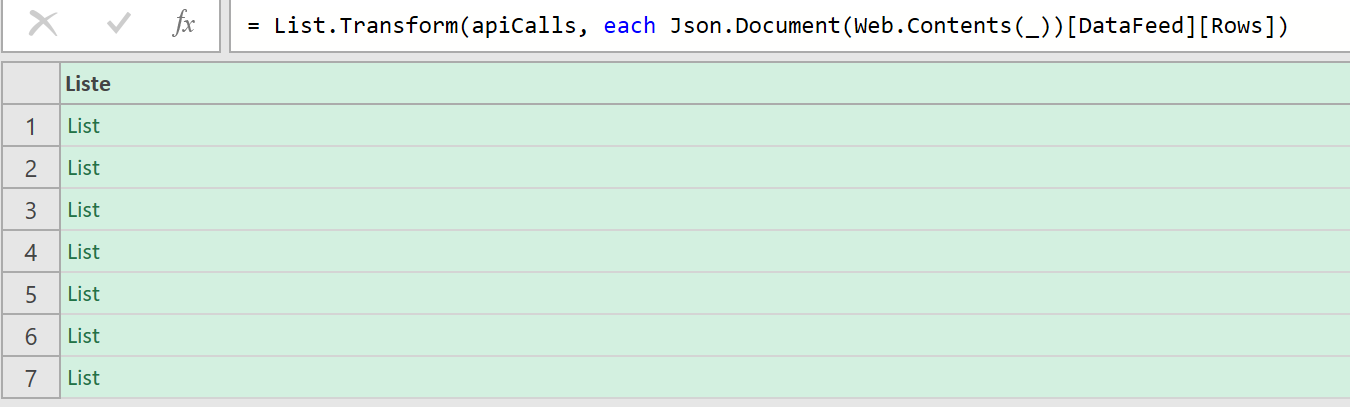
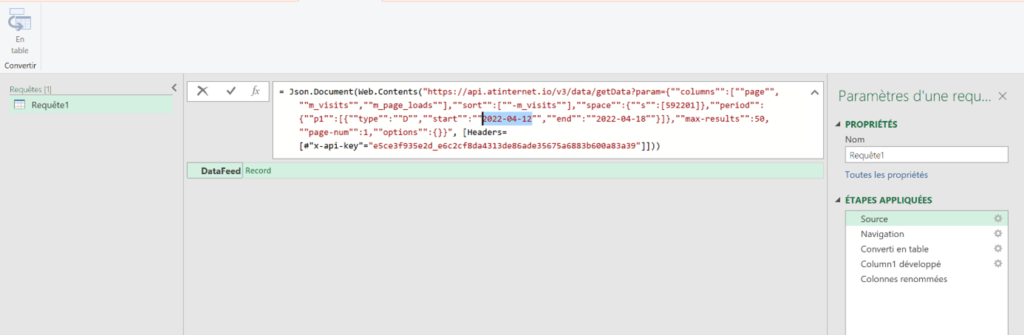
Dans measurements, vous remarquerez que vous avez un petit icône de code « </> » sur chacune d’entre elles : elle va vous donner la structure de base de votre requête API, ce qui est bien pratique pour avoir un exemple de départ.
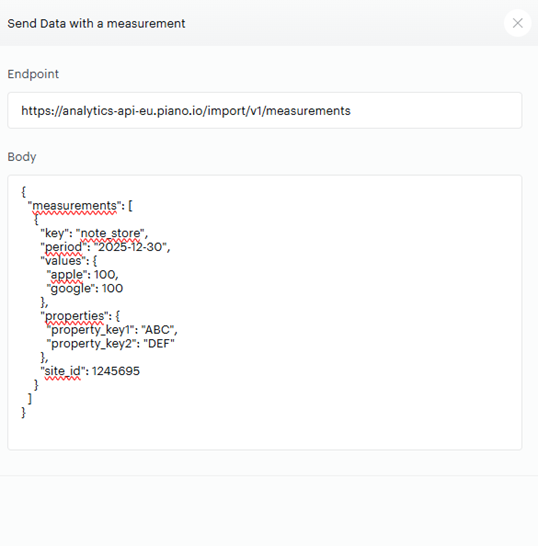
Cette structure contient :
- Votre End Point (dépendamment de votre localisation, dans mon cas il s’agit de l’Europe)
- Le body de la requête, contenant du json avec :
- La clé de votre mesure (« note_store »)
- La période en granularité jour
- Les « values » qui correspondent aux « clés » que vous avez configurées (« apple » et « google »), accompagnées de valeurs fictives
- Des « properties » permettant de contextualiser et ventiler les données (nous n’allons pas l’utiliser tout de suite)
- Un « site_id » qui apparaît car nous avons choisi une portée « site » lors de la configuration (il faudra ici reprendre l’ID de votre site disponible dans le data collection portal)
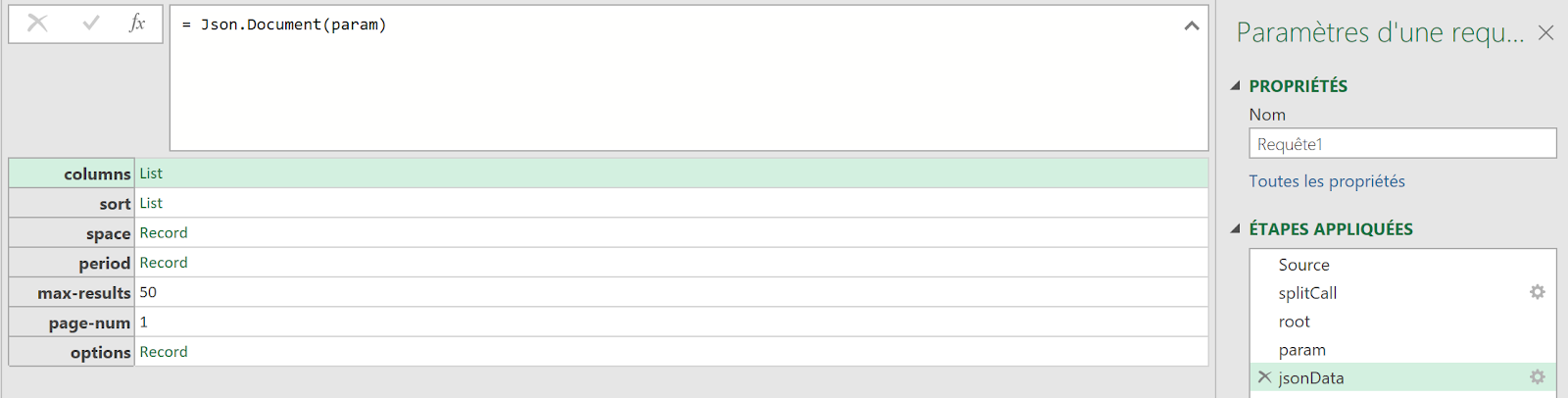
Nous plaçons maintenant nos valeurs de test dans une requête POST :
import requests
import json
# Endpoint API (Europe)
API_URL = "https://analytics-api-eu.piano.io/import/v1/measurements"
# Identifiants
ACCESS_KEY = "votreacceskey"
SECRET_KEY = "votresecretkey"
full_key = f"{ACCESS_KEY}_{SECRET_KEY}"
# Configuration du Payload (le body de la requête)
payload = {
"key": "note_store",
"period": "2025-12-18",
"values": {
"apple": 4.47,
"google": 4.32
},
"site_id": 634856
}
print(json.dumps(payload))
# --- ENVOI DE LA REQUÊTE ---
def push_measurements():
# Headers d'authentification Piano Analytics
headers = {
"Content-Type": "application/json",
"x-api-key": full_key
}
try:
# Envoi POST
response = requests.post(
API_URL,
data=json.dumps(payload),
headers=headers,
timeout=10 # Timeout de sécurité
)
print(response.text)
except requests.exceptions.RequestException as e:
print(f"Erreur de connexion : {e}")
push_measurements()Il ne vous reste plus qu’à chercher dans Data Query les 2 métriques associées et vous devriez voir vos données apparaitre !
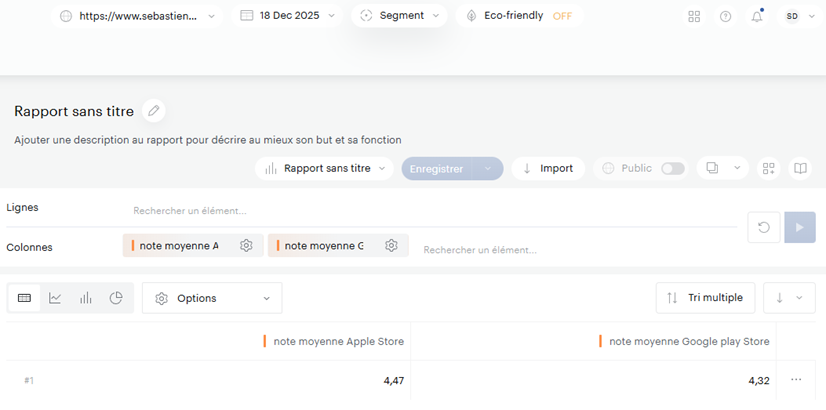
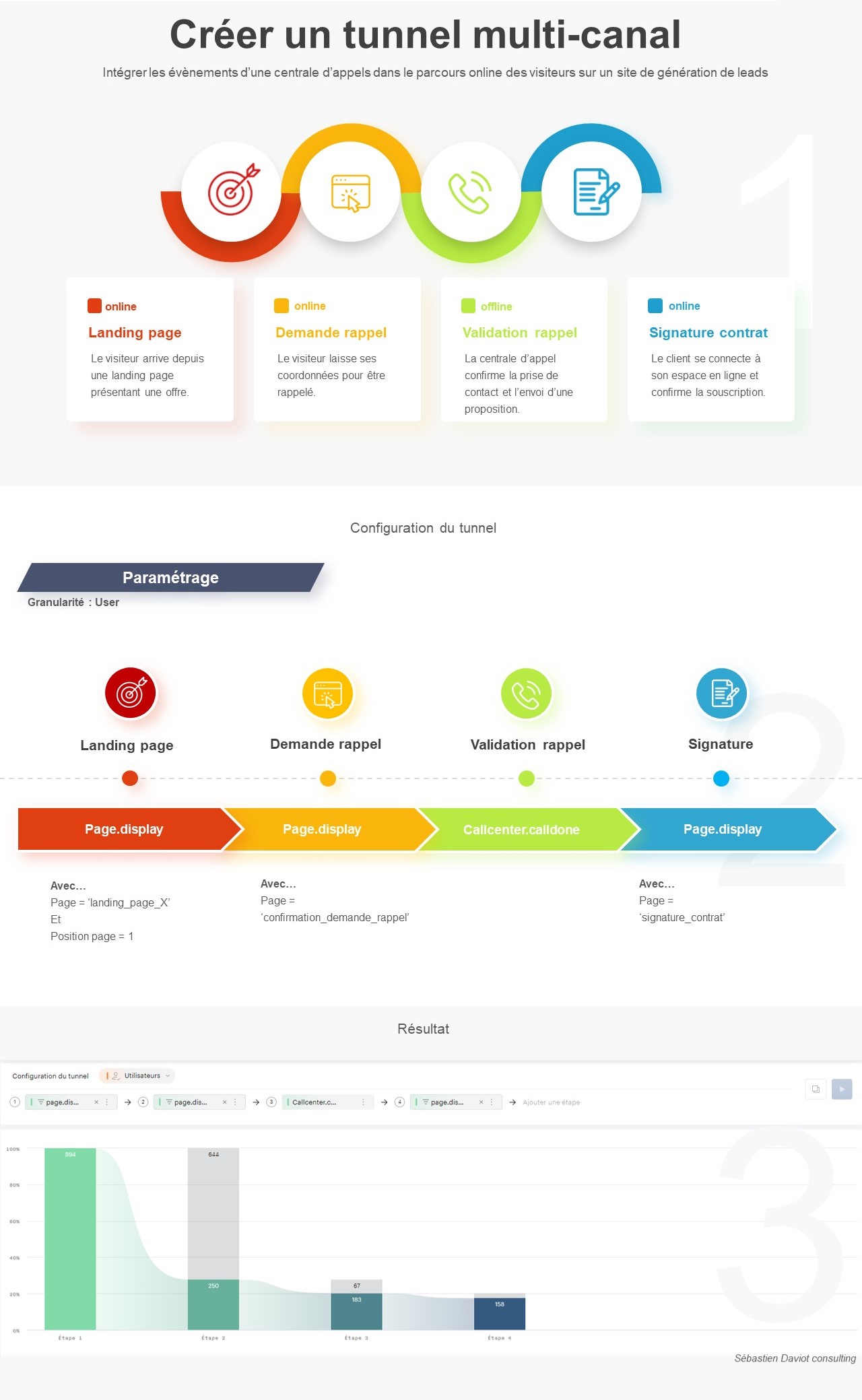
Injecter une série de measurements en un seul appel
Nous savons maintenant comment injecter une mesure pour une journée, mais notre objectif est évidemment de le faire sur l’ensemble de notre historique .
Pour cela, nous n’allons pas boucler sur chaque jour pour faire un appel, mais plutôt injecter toutes nos données journalières dans un seul appel.
Pour cela, nous allons devoir ajuster 2 éléments dans notre appel API :
- Le end point, qui se terminera maintenant par « /batch »
- Le format du body, qui sera maintenant du ndjson (un json plus compacté en ligne)
Voici notre code actualisé, qui contient maintenant 2 jours de données .
import requests
import json
# --- CONFIGURATION ---
# ATTENTION : L'URL change pour le multi-import ! (Ajout de /batch à la fin)
API_URL = "https://analytics-api-eu.piano.io/import/v1/measurements/batch"
ACCESS_KEY = "accessKey"
SECRET_KEY = "secretKey"
full_key = f"{ACCESS_KEY}_{SECRET_KEY}"
# --- DONNÉES (LISTE) ---
data_list = [
{
"site_id": 634856,
"key": "note_apple_store",
"period": "2025-12-20",
"values": {
"apple": 4.55,
"google": 4.30
}
},
{
"site_id": 634856,
"key": "note_apple_store",
"period": "2025-12-21",
"values": {
"apple": 4.60,
"google": 4.35
}
}
]
# --- CONVERSION EN NDJSON (Newline Delimited JSON) ---
ndjson_payload = "\n".join([json.dumps(item) for item in data_list])
print("Format NDJSON généré pour l'endpoint BATCH :")
print(ndjson_payload)
# --- ENVOI ---
def push_measurements_ndjson():
headers = {
"Content-Type": "application/x-ndjson",
"x-api-key": full_key
}
try:
response = requests.post(
API_URL,
data=ndjson_payload,
headers=headers,
timeout=10
)
print(response.text)
except Exception as e:
print(f"❌ Erreur : {e}")
push_measurements_ndjson()
Le ndjson en sortie :
{"site_id": 634856, "key": "note_apple_store", "period": "2025-12-20", "values": {"apple": 4.55, "google": 4.3}}
{"site_id": 634856, "key": "note_apple_store", "period": "2025-12-21", "values": {"apple": 4.6, "google": 4.35}}
Et nous voilà maintenant avec 2 jours de données pour nos stores (avec une moyenne appliquée en cas d’agrégation des 2 jours) :
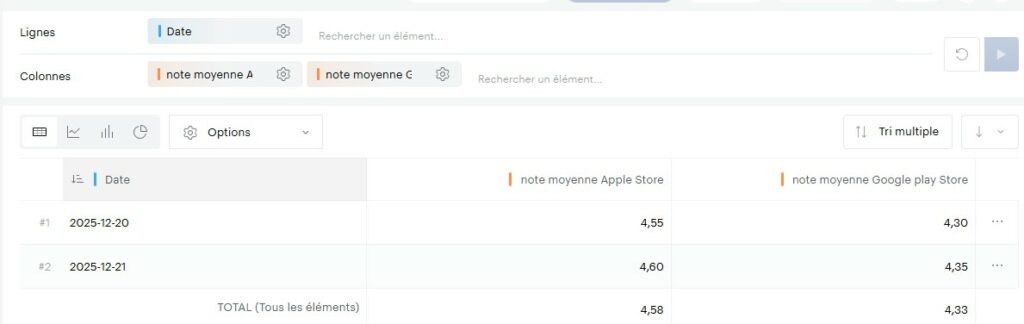
Maintenant que nous avons compris les bases, nous allons pouvoir passer à l’injection de nos données réelles. Pour chaque étape, je vous présenterai dorénavant juste un extrait du ndjson et pas le code python en entier. Pour ceux souhaitant aller sous le capot, je vous renvoie une nouvelle fois vers le dernier chapitre de l’article.
Description de nos données
Nos données d’exemples ici présentes proviennent de l’application Mistral AI pour les 2 stores :
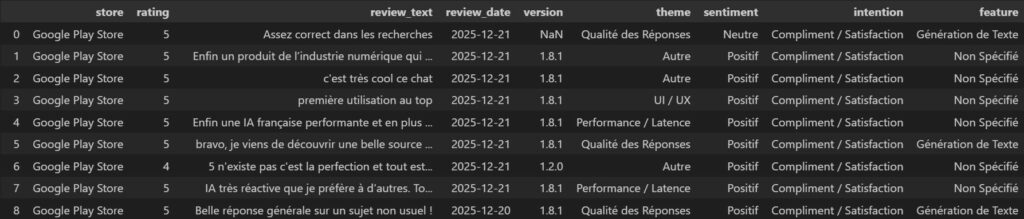
Sa méthode d’extraction et d’enrichissement fait écho à mon article précédent, que je vous conseille vivement de consulter si vous souhaitez comprendre toute la machinerie en détail, mais pour faire très simple : un script python va exploiter des librairies Python et des API ouvertes pour récupérer les avis ainsi que quelques informations de contexte (date, version de l’app), fusionner les 2 stores dans un seul tableau, puis envoyer les avis à l’API de Gemini pour enrichir le data set avec des informations qualitatives :
- Quel est le thème principal de l’avis ?
- Quel est son sentiment global ?
- Quelle est l’intention derrière cet avis ?
- Quelle est la feature principale abordée dans l’avis, s’il y en a une ?
Si vous souhaitez faire de même, une fois encore je vous renvoie à la fin de l’article .
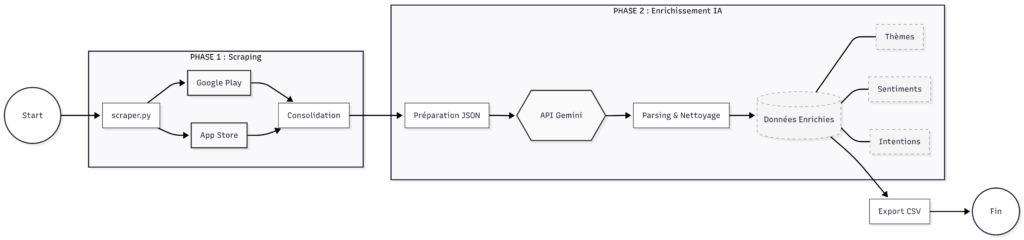
Création de métriques calculées à partir des measurements
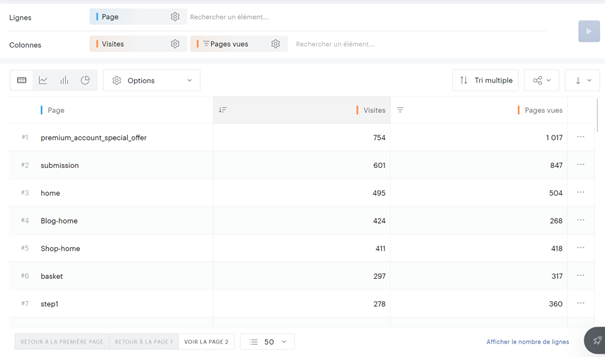
Maintenant que nous avons tous nos avis, nous allons pouvoir créer une agrégation sur la date et le store afin d’obtenir notre note moyenne par jour :
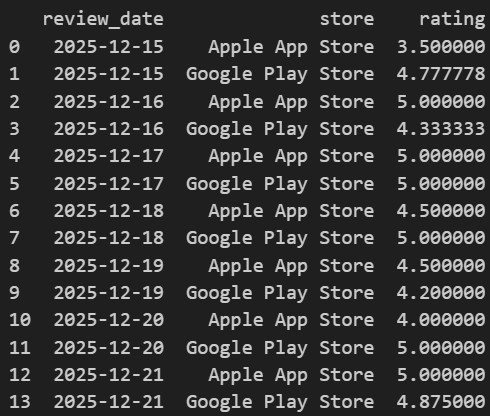
Pour ensuite pousser ces notes dans notre body en ndjson :
{"site_id": 634856, "key": "note_store", "period": "2025-12-15", "values": {"apple": 3.5, "google": 4.78}}
{"site_id": 634856, "key": "note_store", "period": "2025-12-16", "values": {"apple": 5.0, "google": 4.33}}
{"site_id": 634856, "key": "note_store", "period": "2025-12-17", "values": {"apple": 5.0, "google": 5.0}}
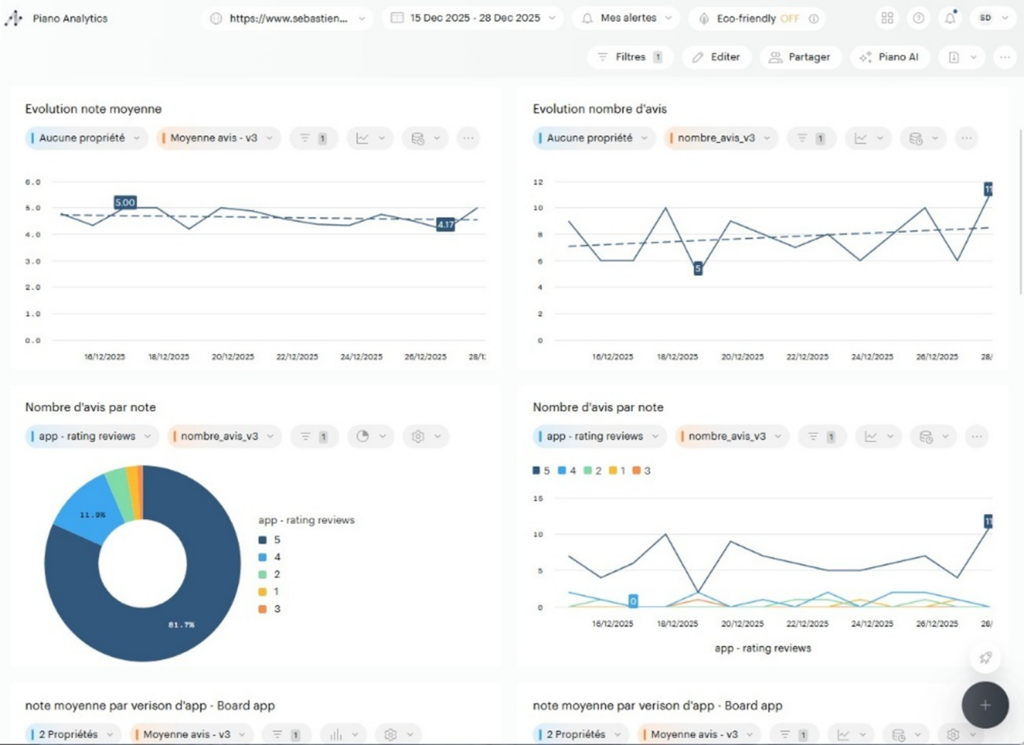
…Et nous obtenons enfin de premières courbes dans Piano Analytics !

Cependant, un problème de calcul va surgir au moment des agrégations sur la semaine : il va réaliser une moyenne à partir de moyennes journalières, ce qui est statistiquement faux . En effet, ici chaque jour de donnée va avoir le même poids dans le calcul, sans prendre en compte que le nombre d’avis journalier varie…
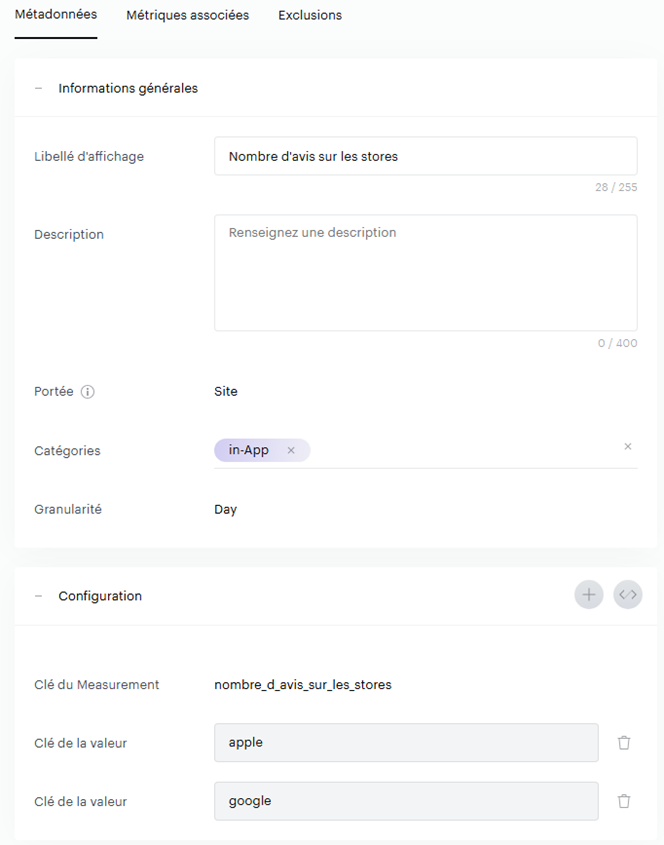
Nous allons donc revoir notre méthodologie pour calculer dynamiquement la moyenne à partir du nombre d’avis :
- Créer une mesure qui remontera le nombre d’avis journaliers, avec une agrégation de type « Sum ».
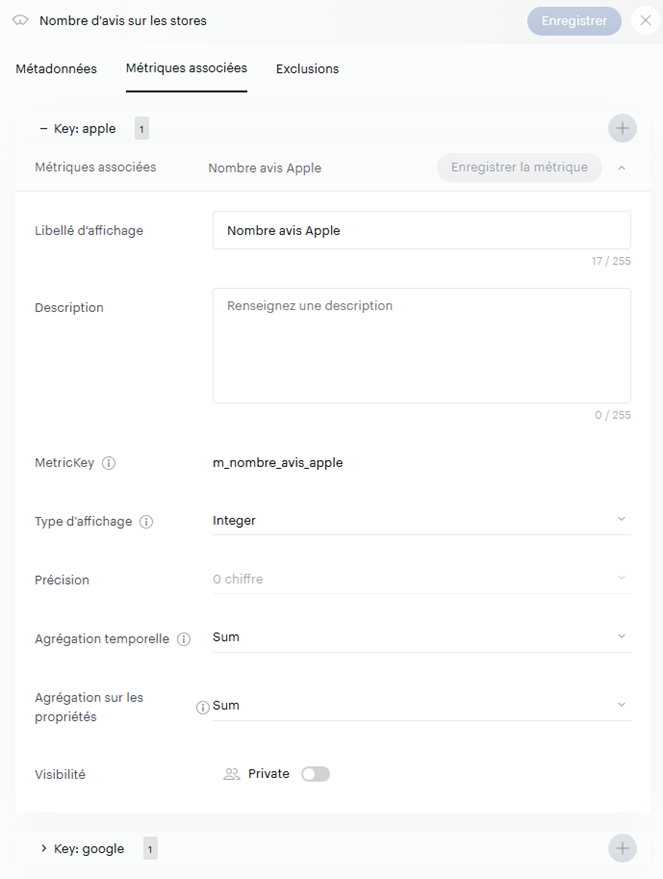
2. Créer une mesure qui somme les notes sur 5 pour chaque jour, avec une agrégation également de type « Sum ».


3. On adapte notre ndjson pour maintenant pousser ces 2 informations pour chaque jour et chaque Store.
{"site_id": 634856, "key": "somme_des_notes_sur_5", "period": "2025-12-15", "values": {"apple": 7, "google": 43}}
{"site_id": 634856, "key": "nombre_d_avis_sur_les_stores", "period": "2025-12-15", "values": {"apple": 2, "google": 9}}
{"site_id": 634856, "key": "somme_des_notes_sur_5", "period": "2025-12-16", "values": {"apple": 5, "google": 26}}
{"site_id": 634856, "key": "nombre_d_avis_sur_les_stores", "period": "2025-12-16", "values": {"apple": 1, "google": 6}}
4. On crée une métrique calculée pour chaque store, qui va diviser la somme des notes par le nombre d’avis
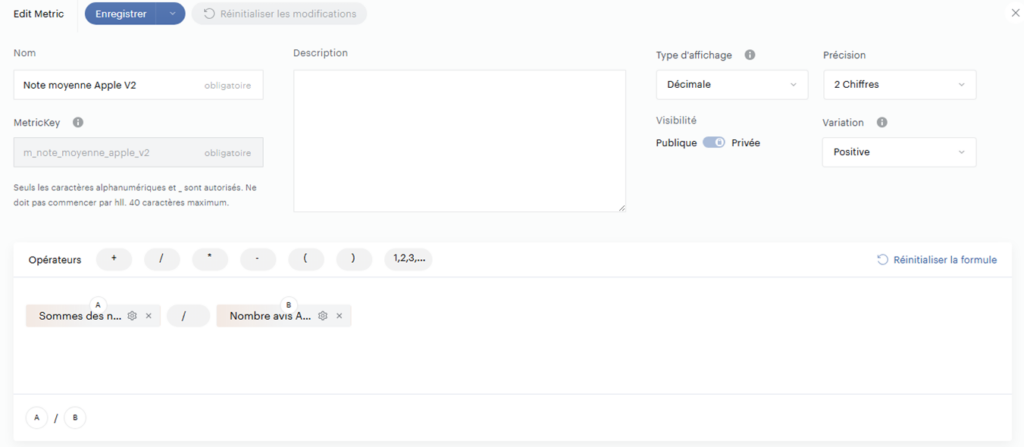
Et voilà ! Comme nous avons la possibilité d’effectuer des calculs sur nos measurements, notre moyenne est donc maintenant juste quel que soit le type d’agrégation réalisé !

Exploitation des propriétés standards de votre data model
Depuis le début, nous créons pour chaque measurement 2 clés distinctes pour chaque store, ce qui comporte des inconvénients (lourdeurs dans la déclaration des mesures et dans leur exploitation, puisque tout est multiplié par 2).
Une autre méthode serait d’associer chacun de nos stores à une propriété de notre data model qui remonte déjà plus ou moins cette information, possibilité qui est offerte par les measurements . Dans mon cas, j’ai utilisé la propriété standard « OS – Famille (os_group) » qui remonte le système d’exploitation du visiteur : Android ou iOS.
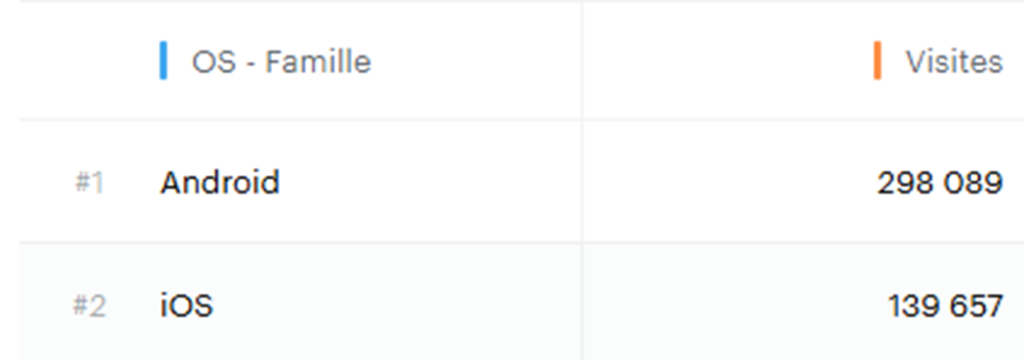
Nous allons donc revoir une nouvelle fois nos measurements (promis c’est la dernière fois) pour déclarer une mesure avec une seule clé pour nos 2 indicateurs (Somme des avis et nombre d’avis) sans distinguer l’origine du store :
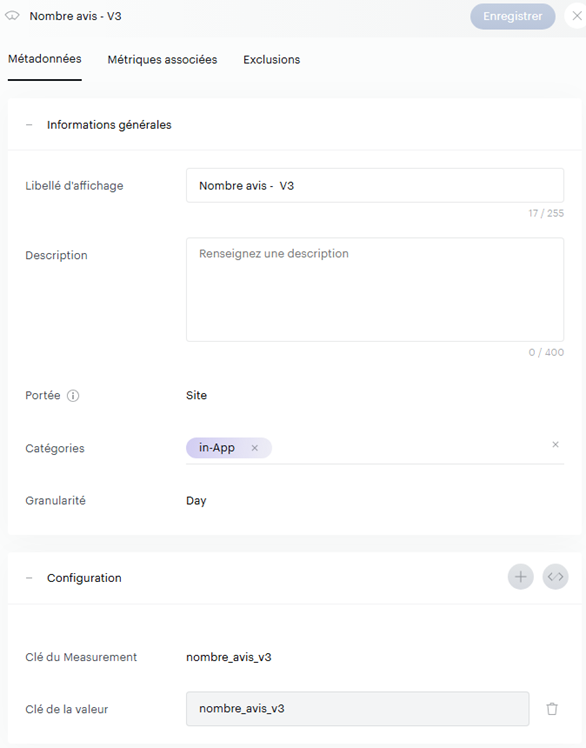
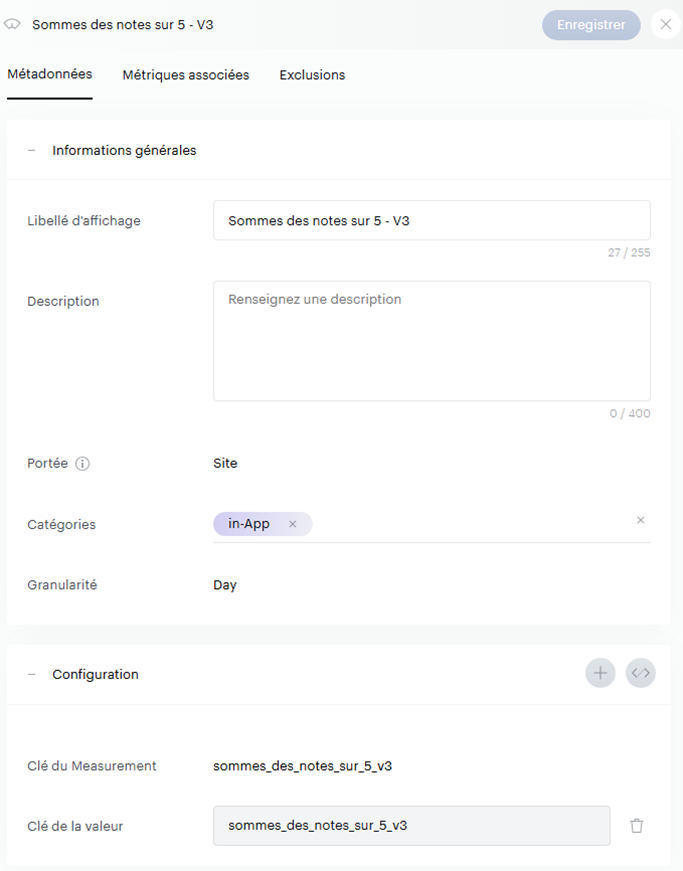
On adapte ensuite notre ndjson pour passer l’information dans la section des properties, en faisant bien attention de suivre la nomenclature des OS du processing Piano pour os_group (« Android » pour le Google Play Store, « iOS » pour l’Apple Store) :
{"site_id": 634856, "key": "sommes_des_notes_sur_5_v3", "period": "2025-12-15", "properties": {"os_group": "iOS"}, "values": {"sommes_des_notes_sur_5_v3": 7}}
{"site_id": 634856, "key": "nombre_avis_v3", "period": "2025-12-15", "properties": {"os_group": "iOS"}, "values": {"nombre_avis_v3": 2}}
{"site_id": 634856, "key": "sommes_des_notes_sur_5_v3", "period": "2025-12-15", "properties": {"os_group": "Android"}, "values": {"sommes_des_notes_sur_5_v3": 43}}
{"site_id": 634856, "key": "nombre_avis_...On crée à nouveau une métrique calculée pour diviser les 2 valeurs et on obtient un magnifique graphique qui affiche l’évolution des notes sur les 2 OS :
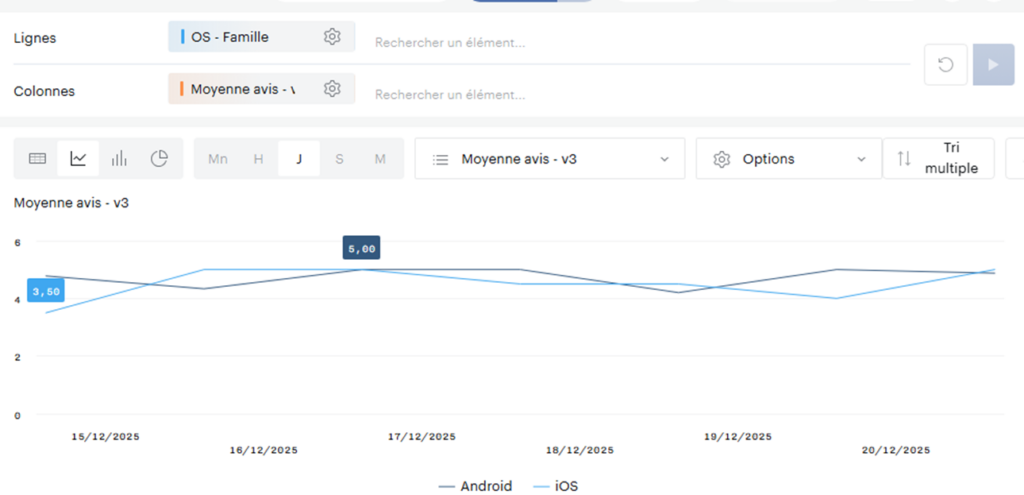
Mais l’avantage ne s’arrête pas là puisque vous avez maintenant la possibilité de rajouter vos measurements dans des tableaux contenant déjà des données Analytics (plutôt pratique pour ensuite créer vos boards) :

Et on peut même aller plus loin en mixant dans une métrique calculée des données analytics et des données issues de measurements : imaginons que je souhaite suivre le nombre d’avis laissés pour 10 000 visites sur mon app . Il me suffit alors de diviser le nombre d’avis par le nombre de visites et de multiplier le tout par 10 000 dans une métrique calculée :
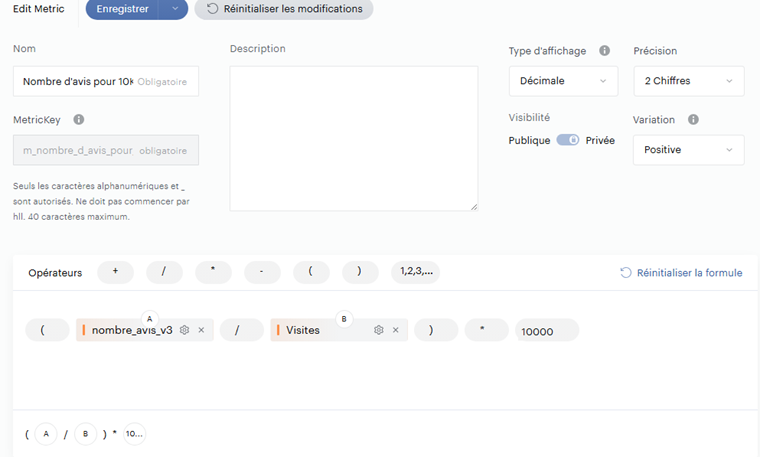
Et ajouter cette nouvelle métrique dans mon data set :

Bien, maintenant qu’on a la logique, pourquoi ne pas continuer l’optimisation ? On récupère via les stores les versions de l’application qui ont été utilisées pour laisser l’avis . Cette information existe également dans le data model de Piano : app_version .
On va donc mettre dans notre ndjson le nombre d’avis et la somme d’avis pour :
- Chaque jour
- Et chaque OS (via
os_group) - Et chaque version d’application (via
app_version)
{"site_id": 634856, "key": "sommes_des_notes_sur_5_v3", "period": "2025-12-15", "properties": {"os_group": "iOS", "app_version": "1.7.0"}, "values": {"sommes_des_notes_sur_5_v3": 7}}
{"site_id": 634856, "key": "nombre_avis_v3", "period": "2025-12-15", "properties": {"os_group": "iOS", "app_version": "1.7.0"}, "values": {"nombre_avis_v3": 2}}
{"site_id": 634856, "key": "sommes_des_notes_sur_5_v3", "period": "2025-12-15", "properties": {"os_group": "Android", "app_version": "1.6.1"}, "values": {"s...Le résultat dans Piano :
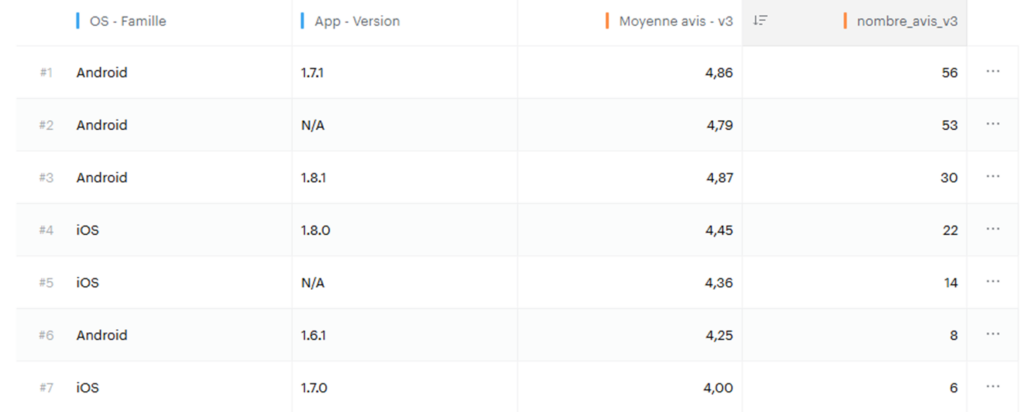
Exploitation de propriétés custom pour enrichir l’analyse
En réalité, notre data set regorge d’informations qui n’ont pas encore été poussées vers Piano (note laissée, thème abordé, sentiment…) :
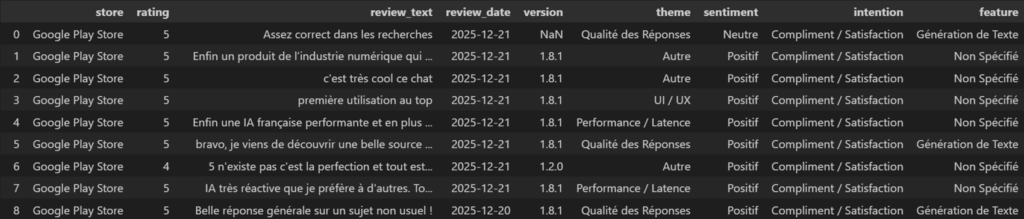
Et là, clairement, il n’existe pas de propriétés standards pour faire cela. Nous allons donc les créer spécifiquement pour les measurements :
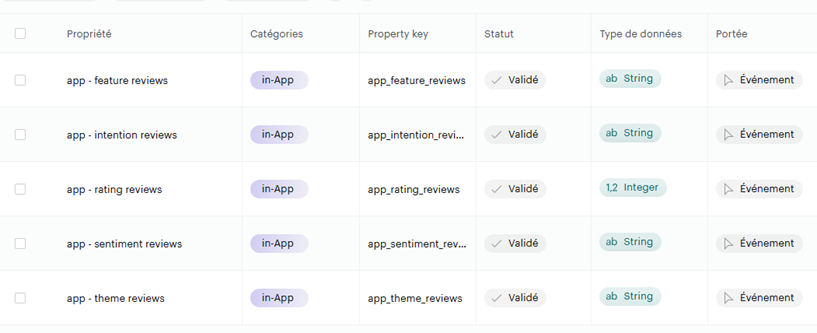
Et rajouter ces informations dans l’agrégation de notre dataset, pour finalement les pousser dans notre ndjson :
{"site_id": 634856, "key": "sommes_des_notes_sur_5_v3", "period": "2025-12-15", "properties": {"os_group": "iOS", "app_version": "1.7.0", "app_rating_reviews": 2, "app_theme_reviews": "Qualit\u00e9 des R\u00e9ponses", "app_sentiment_reviews": "N\u00e9gatif", "app_intention_reviews": "Plainte / Insatisfaction", "app_feature_reviews": "M\u00e9morisation / Contexte"}, "values": {"sommes_des_notes_sur_5_v3": 2}}
{"site_id": 634856, "key": "nombre_avis_v3", "period": "2025-12-15", "properties": {"os_group": "iOS", "app_version": "1.7.0", "app_rating_reviews": 2, "app_theme_reviews": "Qualit\u00e9 des R\u00e9ponses", "app_sentiment_reviews": "N\u00e9gatif", "app_intention_reviews": "Plainte / Insatisfaction", "app_feature_reviews": "M\u00e9morisation / Contexte"}, "values": {"nombre_avis_v3": 1}}
{"site_id": 634856, "key": "sommes_des_notes_sur_5_v3", "period": "2025-12-15", "properties": {"os_group": "iOS", "app_version": "1.7.0", "app_rating_reviews": 5, "app_theme_reviews": "Autre", "app_sentiment_reviews": "Positif", "app_intention_reviews": "Compliment / Satisfaction", "app_feature_reviews": "Non Sp\u00e9cifi\u00e9"}, "values": {"sommes_des_notes_sur_5_v3": 5}}
{"site_id": 634856, "key": "nombre_avis_v3", "period": "2025-12-15", "properties": {"os_group": "iOS", "app_version": "1.7.0", "app_rating_reviews": 5, "app_theme_reviews": "Autre", "app_sentiment_reviews": "Positif", "app_intention_reviews": "Compliment / Satisfaction", "app_feature_reviews": "Non Sp\u00e9cifi\u00e9"}, "values": {"nombre_avis_v3": 1}}
{"site_id": 634856, "key": "sommes_des_notes_sur_5_v3", "period": "2025-12-15", "properties": {"os_group": "Android", "app_version": "1.6.1", "app_rating_reviews": 4, "app_theme_reviews": "Autre", "app_sentiment_reviews": "Positif", "app_intention_reviews": "Compliment / Satisfaction", "app_feature_reviews": "Non Sp\u00e9cifi\u00e9"}, "values": {"sommes_des_notes_sur_5_v3": 4}}Le résultat :
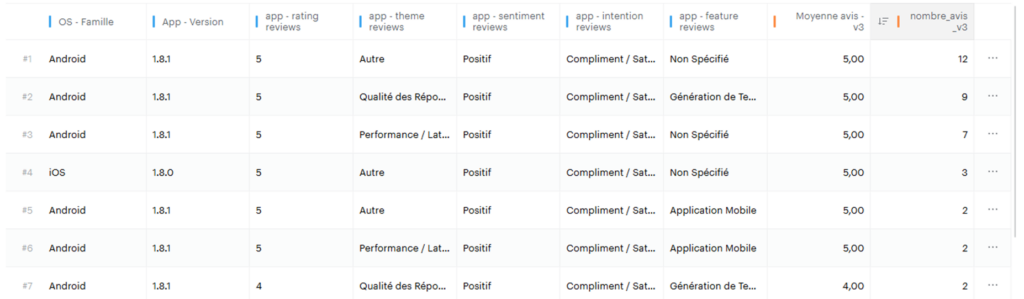
Il ne vous reste maintenant plus qu’à monter vos data set pour créer votre board dédié à vos notes de stores !
Automatisation du processus
Pour ceux qui souhaitent mettre en place ce type de workflow, je vous mets à disposition les fichiers dans un dossier github (pensez au readme, il y a un peu de setup !), ainsi qu’une vidéo explicative du processus
- Le github : https://github.com/SebastienDa/mesurements_piano_analytics_stores_app
- La vidéo précédente pour la compréhension du scraper, de l’Api Gemini et du format d’output en Pydantic : https://www.youtube.com/watch?v=L9r-RCiE-dg
Conclusion : Une alternative agile à la BI pour des besoins ciblés
Comme nous l’avons démontré tout au long de ce cas pratique, la véritable puissance des Measurements ne réside pas dans l’injection brute de données, mais bien dans leur intégration intelligente au Data Model. C’est l’exploitation des propriétés Piano (comme l’OS ou la version) combinée à la flexibilité des métriques calculées qui change totalement la donne.
Cette approche s’avère particulièrement pertinente dans des environnements d’entreprise contraints, où le déploiement d’outils de BI tiers (Tableau, PowerBI) est complexe, ou lorsque l’accès aux données brutes (Raw Data) pour des croisements externes est limité.
Le fait de centraliser ces informations externes directement dans Piano Analytics présente un avantage opérationnel majeur : vous offrez à vos utilisateurs l’accès à un système unifié, via une interface qu’ils maîtrisent déjà, sans la lourdeur de maintenance d’un ETL externe complexe.
Si cette fonctionnalité n’a pas vocation à remplacer un Data Warehouse pour des jointures fines à l’échelle de l’identifiant visiteur (ce n’est pas son but), elle est en revanche redoutablement efficace pour enrichir vos analyses de tendances et de corrélations macro.
Au-delà des avis des stores, cette logique est transposable à de multiples sources de données pour contextualiser votre trafic (qui sont par ailleurs déjà abordés dans la documentation Piano) :
- Données météorologiques (impact du temps sur la fréquentation) ;
- Données CMP (suivi des taux d’acceptation et de refus) ;
- Search Console (intégration des données SEO) ;
- Données métier internes (stocks, ventes offline, etc.).
La mécanique est là, il ne vous reste plus qu’à choisir les données qui apporteront le plus de valeur à vos boards.