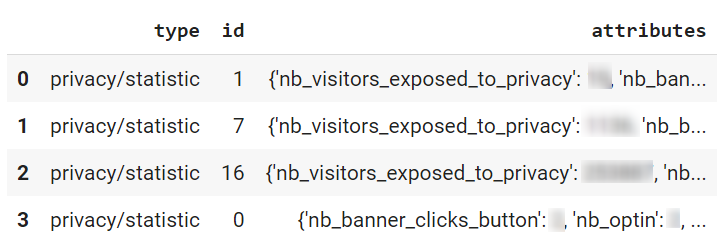
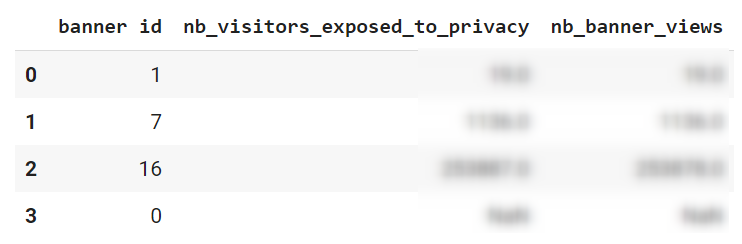
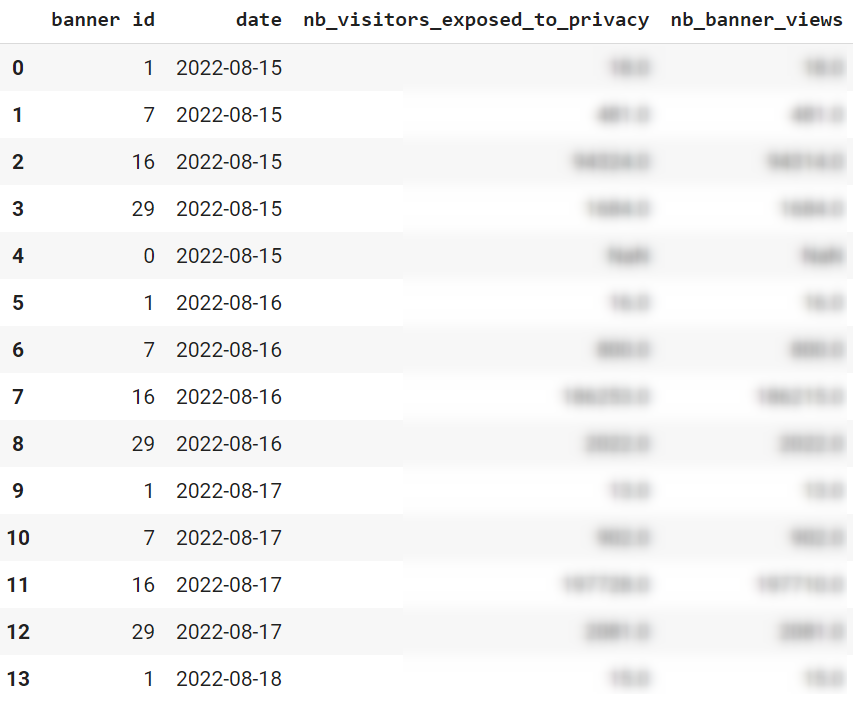
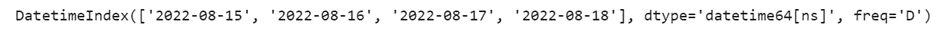Si votre entreprise utilise Piano analytics depuis un certain temps, un grand nombre de propriétés personnalisées ont certainement été créées dans votre data model. Et si plusieurs équipes de votre organisation travaillent de manière indépendante sur Piano Analytics ou si un certain turn over existe, il se peut que vous ayez perdu le fil de ce qui est réellement présent ET utile dans votre data model.
Vous pourriez alors vous retrouver avec un data model dégradé comportant des propriétés :
- En doublon (ayant la même fonction, pas exactement le même nom mais remontant les mêmes valeurs)
- Faux doublons (ayant la même fonction mais pas exactement le même nom et par exactement les mêmes valeurs)
- Non exploitées (plus aucune données ne remontent depuis un certain temps)
- Mono valeurs (remonte systématiquement la même valeur)
Vous pourriez peut-être être étonné du terme « data model dégradé » que j’ai utilisé. En quoi avoir des doublons ou des propriétés sans donnée peut impacter l’exploitation quotidienne des données de votre entreprise ? Laissez-moi vous avancer quelques arguments.
La problématique d’avoir un data model non optimal
Le stock de propriétés personnalisées n’est pas infini
Selon votre compte, vous bénéficiez de 500 à 1 000 propriétés disponibles dans votre data model. Ce chiffre peut vous paraitre inatteignable mais vous seriez surpris de voir à quel point cela peut aller vite, surtout quand plusieurs équipes se partagent l’outil. Cette limite atteinte, vous ne pourrez plus créer de nouvelle propriété sans upgdrader votre compte ou le cleaner. Le compteur de vos propriétés personnalisées est disponible dans votre data model. Pour avoir le bon compte, vous devez appliquer les filtres suivants :
- Entités : propriétés personnalisées
- Statuts : validé
- Visibilité : Visible ET masquée

Compréhension du data model plus complexe
Il faut avoir en tête que chaque propriété créée sera ajoutée dans la liste des éléments disponibles dans Data Query, dans les critères de segmentation ou encore dans le « croiser avec » d’Explorer…Compliqué de s’y retrouver si cette liste comporte des doublons ou des valeurs sans aucune donnée.
Possibles erreurs d’analyses
Si 2 propriétés ont des noms proches mais ne remontent pas exactement la même information, un utilisateur peut potentiellement les confondre et donc analyser des données qui ne concernaient pas sa recherche initiale. Pire, il peut aussi mettre en place une nouvelle règle de processing dans le data model, venant modifier les données de la mauvaise propriété et ainsi impacter irrémédiablement une autre équipe.
Non transversalité des données
Une propriété pouvant être transverse à plusieurs sites, il est dommage de ne pas harmoniser la manière de faire remonter une information. Si vous avez 2 propriétés quasi identiques mais dont une uniquement utilisée sur votre site web et l’autre uniquement sur votre application, il sera beaucoup plus difficile d’analyser ces 2 valeurs au global.
Notre objectif sera donc d’identifier ces propriétés problématiques afin de les désactiver du data model et ainsi regagner en clarté.
Extraction et première analyse de son data model
Comme nous l’avons vu, vous pouvez accéder à l’ensemble de vos propriétés personnalisées dans votre Data model en filtrant sur « Entités » > « Propriétés personnalisées ». Cette vue vous donne une première lecture de vos propriétés mais l’extract proposé dans « Action » > « Extraire Data model » comporte d’avantage d’informations et nous permettra surtout d’ajouter nos propres annotations.
Voici la définition des différents champs présents dans cet extract :
- propertyKey : clé unique de la propriété, que vous retrouvez notamment dans l’API, ou qui est à utiliser dans votre marquage
- Type : format déclaré de la propriété (string, integer, date…)
- Status : La propriété est-elle encore actives (validated) ? Si oui, alors celle-ci est encore susceptible de remonter des données. Si la propriété est inactive (disabled) elle ne peut alors plus remonter de données, même si votre tracking génère encore des events avec celle-ci
- Hidden : la propriété est-elle disponible dans les analyses Piano Analytics ? Si elle est cachée (hidden=true), alors elle n’apparaitra dans aucun menu. Attention cependant, elle reste disponible pour remonter des données et elle est également requétable dans l’API.
- custom : La propriété est-elle personnalisée (= créée par vous) ?
- Name : Quel est son nom visible dans l’interface ?
- Description : Quel est la définition renseignée avec la propriété au moment de sa déclaration ?
- usedInImport : la propriété est-elle utilisée pour réaliser des imports de données externes ?
- Tags : quels sont les mot-clés qui ont été associés à la propriété au moment de sa déclaration ?
Cette liste comportant l’ensemble du data model, nous allons devoir filtrer sur quelques éléments pour isoler nos propriétés personnalisées :
- S’isoler uniquement sur les propriétés personnalisées, avec « custom » = « true »
- Garder uniquement celles qui sont encore actives, avec « Statut » = « validated »
J’aurais tendance à vous conseiller de garder les propriétés cachées « hidden »= »true », puisque celles-ci remontent encore de la données et seraient donc aussi potentiellement cleanables.
C’est normalement déjà fait via l’extract, mais je vous conseille de trier le tableau sur la colonne PropertyKey, afin de voir apparaitre les doublons plus facilement.
Automatiser la détection des propriétés problématiques avec Python
Ce fichier nous donne une première base d’information, mais il ne peut en l’état pas nous mettre en évidence les propriétés sans données, ou celles avec des valeurs similaires. Il faudrait donc le faire manuellement, ligne par ligne, avec l’aide de l’interface.
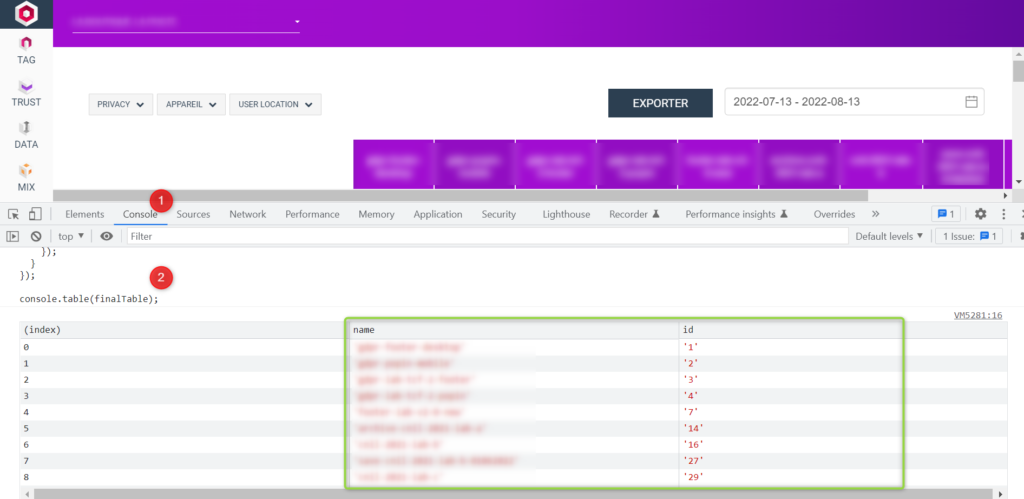
Nous allons donc agrémenter cela à l’aide d’un petit code qui va aller chercher la présence de données sur chaque propriété grâce à l’API Piano Analytics. A partir de là, nous allons pouvoir automatiser un grand nombre de vérifications (doublon, faux-doublon, aucune donnée…)
Création d’un appel API générique
La première étape avec être de créer l’appel API qui nous servira de base pour déterminer :
- Si une propriété récolte de la donnée (=nombre d’events où la propriété est non nulle) ?
- Si oui, quel est le nombre de valeurs associées et quelles sont les top valeurs ?
- Si ces valeurs se retrouvent dans une autre propriété (=synonyme d’un potentiel doublon) ?
Commençons pas créer le template nécessaire dans data Query :
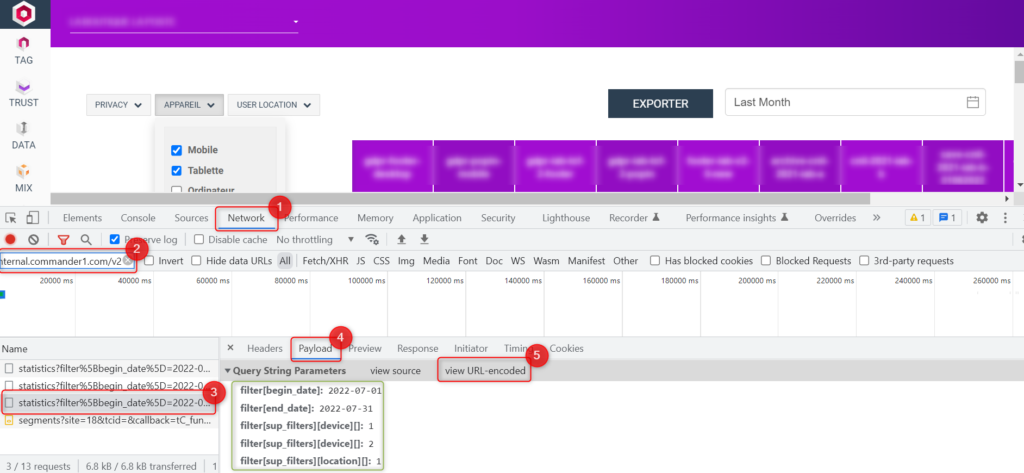
- Sélectionnez la propriété personnalisée de votre choix (peu importe laquelle) avec la métrique « évènements ».
- Sélectionnez l’ensemble de vos sites de niveaux 1 via la case « tous vos sites » dans le menu de sélection (et oui, une propriété peut potentiellement remonter sur un S1 obscure dont vous n’avez pas connaissance).
- Vous allez maintenant sélectionner la période sur laquelle vous souhaitez vérifier la présence de données. A vous de déterminer la période suffisante pour décider de supprimer une propriété qui ne remonte plus de donnée. De mon côté je vais partir sur les 6 derniers mois.
- Comme nous voulons vérifier la présence de données, assurez-vous bien que l’option « Affichez les lignes N/A » est bien décochée.
Vous devriez vous retrouver avec une liste des valeurs associées à votre propriété, avec un volume d’évènements par valeur et au total :
Vous pouvez maintenant prendre l’appel l’API GET (« Ouvrir dans » > « Copier l’URL API GET ») de votre template et le mettre de côté. Celui-ci sera encodé, aussi je vous conseille de le désencoder afin de le rendre plus manipulable pour la suite.
Création de la clé API
Pour requêter vos données Piano Analytics depuis l’extérieur de l’interface, vous allez devoir obtenir une clé API. Cette clé est liée à votre compte Piano Analytics, vous n’aurez donc pas la même que votre collègue. Vous aurez également accès au même périmètre que celui disponible dans votre interface (même liste de niveaux 1).
Une fois connecté à votre compte, allez dans votre profil puis dans l’onglet Api Keys.
Générez une nouvelle clé et conservez bien l’Access key et surtout la secret key, qui ne vous sera plus donnée par la suite.
Configuration du script Python
Pour utiliser ce code, il vous faudra donc une instance Python disponible. Si vous n’en avez pas, vous pouvez utiliser Le service de notebook en ligne de Google.
Vous allez devoir paramétrer quelques variables afin de rendre le code fonctionnel, mais rien d’insurmontable.
headers = {'x-api-key': "secretKey_accessKey"}
url = 'URL API du template créé précédemment'
topValues = 10 #Nombre de top values qui seront présentées
nbSameValues = 2 #Nombre de valeurs similaires pour ajouter un flag entre 2 propriétés
cheminFichierDM = '/file/datamodel.csv' # Chemin d'accès au data model
cheminresultats = '/file/' #chemin de dépot des résultats- La variable headers va contenir la concaténation de votre clé secrète avec votre clé publique, séparées par un « _ ».
- La variable url contiendra l’URL API que nous avons créée tout à l’heure. Gardez bien en tête que la période sur laquelle les propriétés seront vérifiées est celle que vous avez utilisée dans votre Template (Les 6 derniers mois dans mon exemple)
- La variable topValues vous permet de déterminer le nombre de valeurs d’exemples que vous souhaitez voir apparaitre pour chaque propriété dans le fichier final. Si, par exemple, vous placez « 10 », vous aurez donc les 10 valeurs ayant reçues le plus de trafic sur la période choisie
- La variable nbSameValues vous permet de déterminer le nombre de valeurs similaires entre 2 propriétés pour leur ajouter un flag de similarité. Si par exemple la propriété Alpha a pour top valeurs [‘A’,’B’,’C’,’D’,’E’] et Beta [‘D’,’E’,’F’,’G’,’H’], et que vous avez nbSameValues=2, alors les 2 variables seront flaggées comme similaires (et donc à vérifier). Mais si vous aviez configuré nbSameValues=3, il n’y aurait pas eu de flag car seules 2 valeurs sont communes aux 2 variables.
- La variable cheminFichierDM indique le chemin d’accès du fichier csv extrait depuis votre data model. Ne modifiez pas le fichier extrait, sous peine de voir le script ne pas fonctionner
- Finalement la variable cheminresultats sera le dossier dans lequel les fichiers de résultats seront déposés.
Vous n’avez plus qu’à faire tourner le script complet ! Chaque propriété va générer 2 appels API, qui vont ensuite être traités. Il se peut donc que l’exécution dure plusieurs minutes.
Analyse des résultats
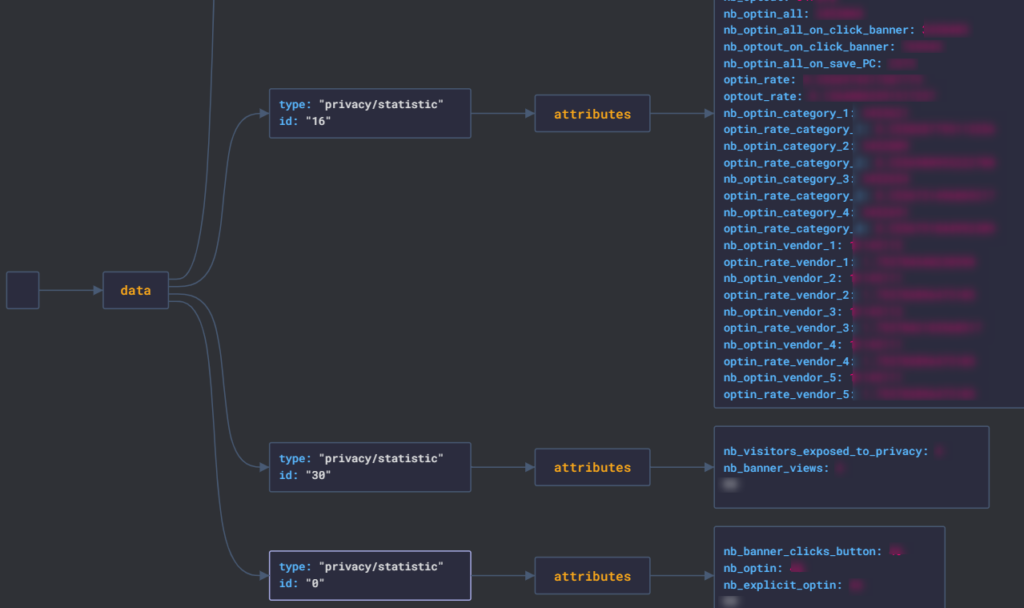
Le script va générer 2 fichiers CSV, stats.csv et check_data_DM.csv. Parcourons-les rapidement ensemble.
Comprendre la qualité de votre data model
Le fichier stats.csv vous indique les métriques clés pour comprendre les principaux points d’attention à avoir concernant votre data model.
- Custom props : Nombre total de propriétés personnalisées testées dans le script
- Nombre de propriétés à vérifier : nombre de propriétés avec au moins un discriminant (points 3 à 6)
- Props sans donnée : nombre de propriétés sans aucune donnée sur la période (= aucun event où la propriété testée avait une valeur non nulle)
- Props avec doublons : nombre de propriétés ayant un nom identique à une autre, synonyme de potentiels doublons
- Props avec valeur unique : nombre de propriétés n’ayant qu’une seule valeur associée
- Props avec valeurs similaires : nombre de propriétés ayant au moins X valeurs identiques avec une autre propriété (X étant le nombre défini dans la variable nbSameValues).
Analyser dans le détail les propriétés problématiques
Le fichier check_data_DM.csv reprend les colonnes de départ du data model, filtré sur les propriétés personnalisées et validées. Des nouvelles colonnes ont été ajoutées par le script pour vous aider dans vos travaux :
- Statut appel : retourne ‘OK’ si l’appel API a bien pu s’effectuer
- Nb résultats : Nombre d’évènements où la propriété avait une valeur non nulle sur la période définie. Vous pouvez filtrer sur « 0 » pour isoler les propriétés sans donnée.
- sample : Top valeurs pour la propriété analysée, sous la forme d’une liste
- Nombre de valeurs différentes : nombre de valeurs différentes pour la propriété analysée. Vous pouvez filtrer sur « 1 » pour isoler les propriétés qui ne remontent qu’une seule valeur
- Doublon ? : retourne la liste des propriétés ayant le même nom (colonne « name ») que la propriété analysée. Filtrez sur une des combinaisons pour analyser ces doublons
- Valeurs similaires avec une autre propriété ? : retourne la liste des propriétés ayant au moins X valeurs identiques avec la propriété analysée. Filtrez sur une des combinaisons pour analyser ces propriétés aux valeurs similaires
- Colonne avec discriminant(s) : indique True si la propriété possède au moins un des discriminants.
Conclusion
Vous avez maintenant toutes les informations pour déterminer les propriétés à conserver de celles qui doivent être désactivées ou fusionnées.
Une propriété sans discriminant ne veut pas dire qu’elle ne mérite pas votre attention. Elle peut par exemple remonter un volume très faible de trafic (quelques centaines d’events) et donc être synonyme d’une remontée partielle des données. Vous pouvez également constater des valeurs obsolètes dans les valeurs d’exemples données dans la colonne « Sample ».
Finalement, ce cleaning sera inlassablement à refaire sans stratégie de gestion de votre data model. Pensez à mettre en place ou gouvernance solide pour la déclaration et le maintien dans le temps des nouvelles propriétés.
Bonne chance 🙂
Le script complet
import pandas as pd
import requests
import json
import numpy as np
import datetime
import time
pd.options.mode.chained_assignment = None
headers = {'x-api-key': "secretKey_accessKey"}
url = 'URL API du template créé précédemment'
topValues = 10 #Nombre de top values qui seront présentées
nbSameValues = 2 #Nombre de valeurs similaires pour ajouter un flag entre 2 propriétés
cheminFichierDM = '/file/datamodel.csv' # Chemin d'accès au data model
cheminresultats = '/file/' #chemin de dépot des résultats
props = pd.read_csv(cheminFichierDM, sep=";", decimal=',', encoding="UTF-8")
props = props[(props['custom'] == True)&(props['status'] =="validated")]
props['Statut appel'] = ''
props['nb resultats'] = ''
props['sample'] = ''
props['nombre de valeurs différentes'] = ''
props['doublon ?'] = ''
props['valeur similaires avec une autre propriété ?'] = ''
urlRootRows = 'https://api.atinternet.io/v3/data/getData?param='
urlRootTotal = 'https://api.atinternet.io/v3/data/getTotal?param='
jsonRowsCall = json.loads(url.split('?param=')[1])
ParamsToRemove = ['sort','max-results','page-num']
jsonTotalCall = json.loads(url.split('?param=')[1])
[jsonTotalCall.pop(x) for x in ParamsToRemove]
for index, row in props.iterrows():
try:
jsonRowsCall['columns'] = ,"m_events"]
jsonTotalCall['columns'] = ,"m_events"]
call = requests.get(urlRootRows+json.dumps(jsonRowsCall), headers=headers)
data = json.loads(call.content)
values = []
for i in list(data['DataFeed']['Rows'])[0:topValues]:
values.append(i])
props['sample'][index] = values
props['nombre de valeurs différentes'][index] = len(list(data['DataFeed']['Rows']))
call = requests.get(urlRootTotal+json.dumps(jsonTotalCall), headers=headers)
data = json.loads(call.content)
props['nb resultats'][index] = data['DataFeed']['Rows'][0]["m_events"]
props['Statut appel'][index] = 'OK'
except:
props['Statut appel'][index] = 'KO'
for index, row in props.iterrows():
testDoublon = props[props['name'] == row['name']]
if len(testDoublon) >1:
props['doublon ?'][index] = list(testDoublon['propertyKey'])
props['valeur similaires avec une autre propriété ?'][index] = []
for indexbis, rowbis in props.iterrows():
if(index != indexbis):
checkSimilars = list(set(row['sample']).intersection(rowbis['sample']))
if len(checkSimilars) >= nbSameValues:
props['valeur similaires avec une autre propriété ?'][index].append(rowbis['propertyKey'])
props['colonne avec discriminant(s)'] = False
props['colonne avec discriminant(s)'][(props['nb resultats'] == 0) | (props['doublon ?'] != '') | (props['nombre de valeurs différentes'] == 1) | (props['valeur similaires avec une autre propriété ?'].astype(str) != '[]')] = True
props.to_csv(cheminresultats+'check_data_DM.csv', sep=";", decimal=',',encoding='utf-8-sig') #Enregistrement du tableau final
stats = {
'Custom props':len(props),
'Nombre de propriétés à vérifier': len(props[(props['nb resultats'] == 0) | (props['doublon ?'] != '') | (props['nombre de valeurs différentes'] == 1) | (props['valeur similaires avec une autre propriété ?'].astype(str) != '[]')]),
'Props sans donnée': len(props[props['nb resultats'] == 0]),
'Props avec doublons' : len(props[props['doublon ?'] != '']),
'Props avec valeur unique':len(props[props['nombre de valeurs différentes'] == 1]),
'Props avec valeurs similaires': len(props[props['valeur similaires avec une autre propriété ?'].astype(str) != '[]'])
}
stats = pd.DataFrame({'propriétés':list(stats.values())}, index=list(stats.keys()))
stats.to_csv(cheminresultats+'stats.csv', sep=";", decimal=',',encoding='utf-8-sig')