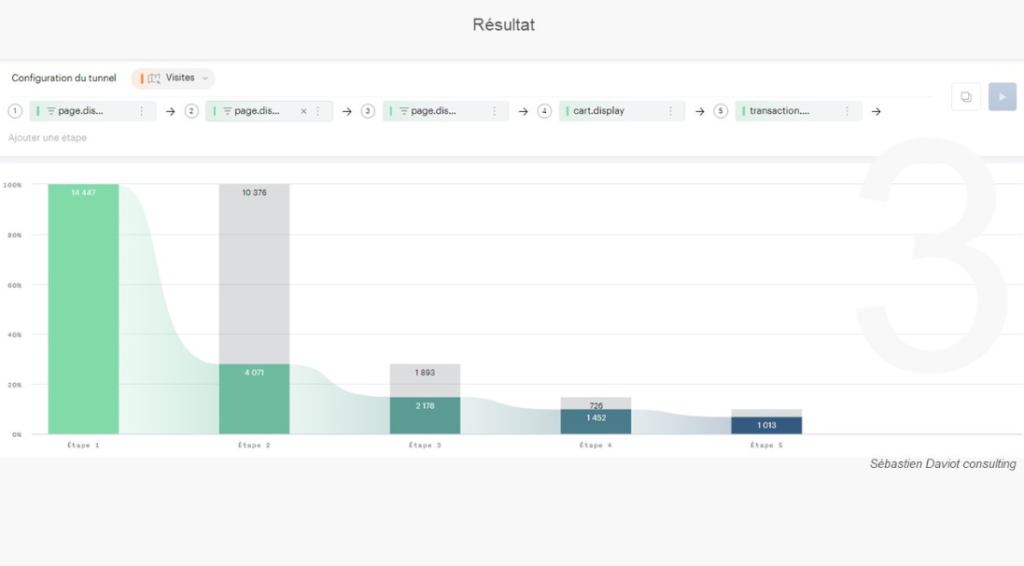
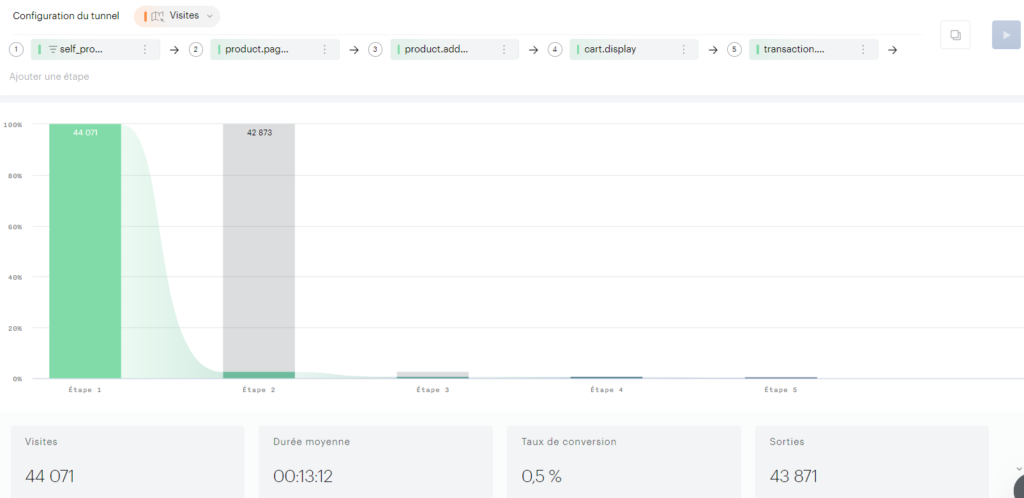
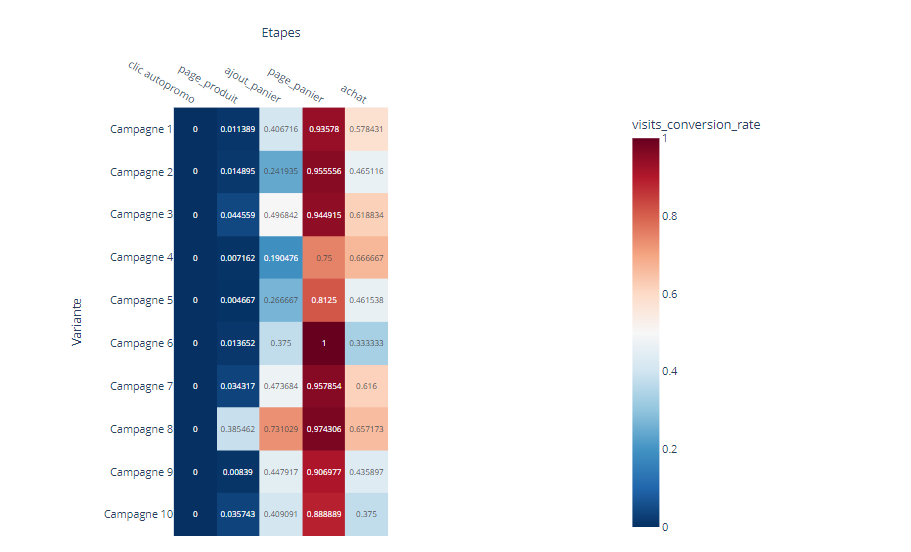
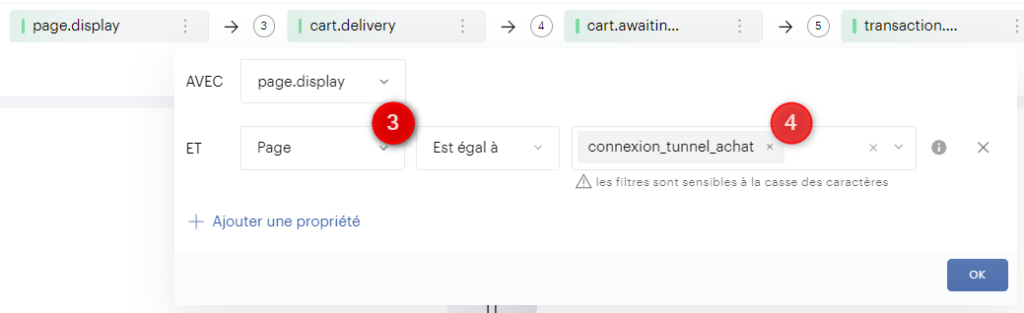
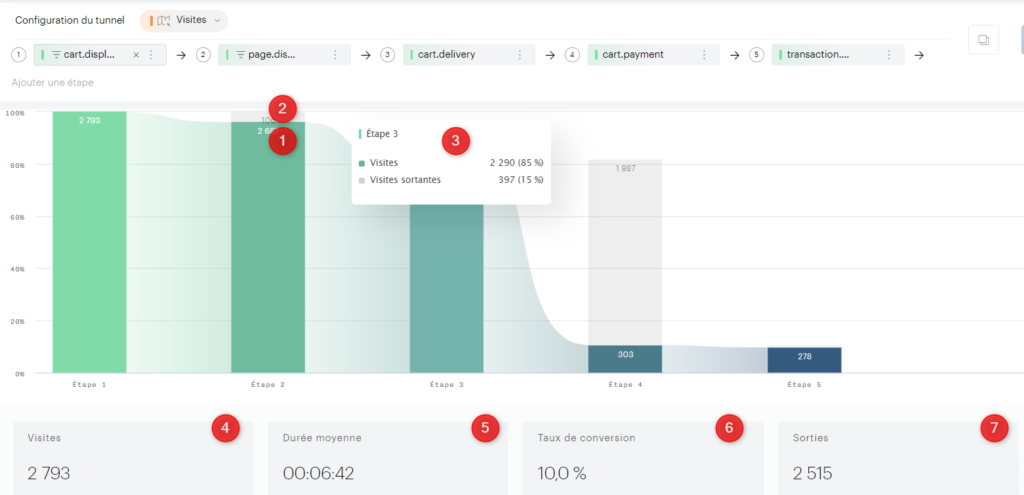
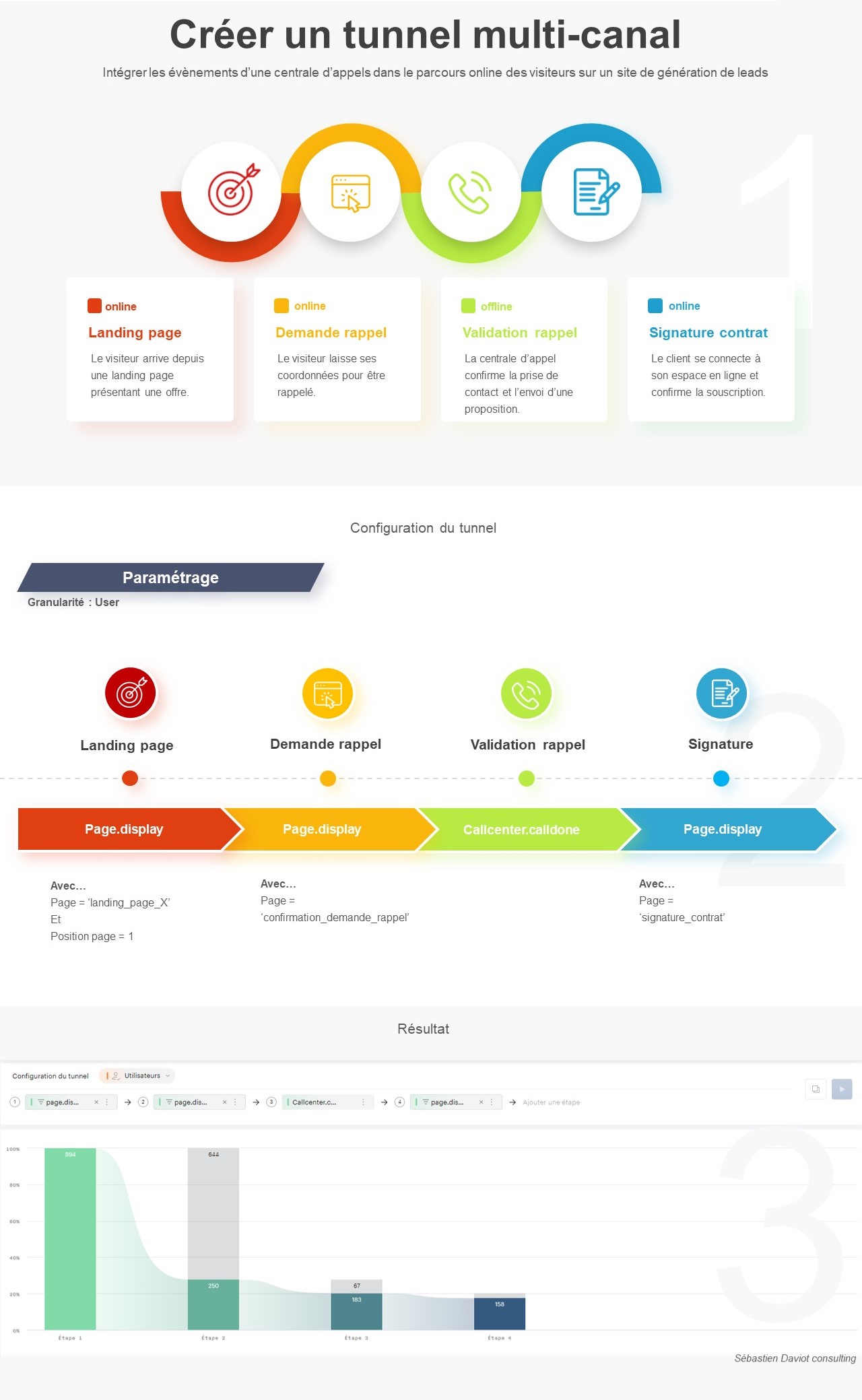
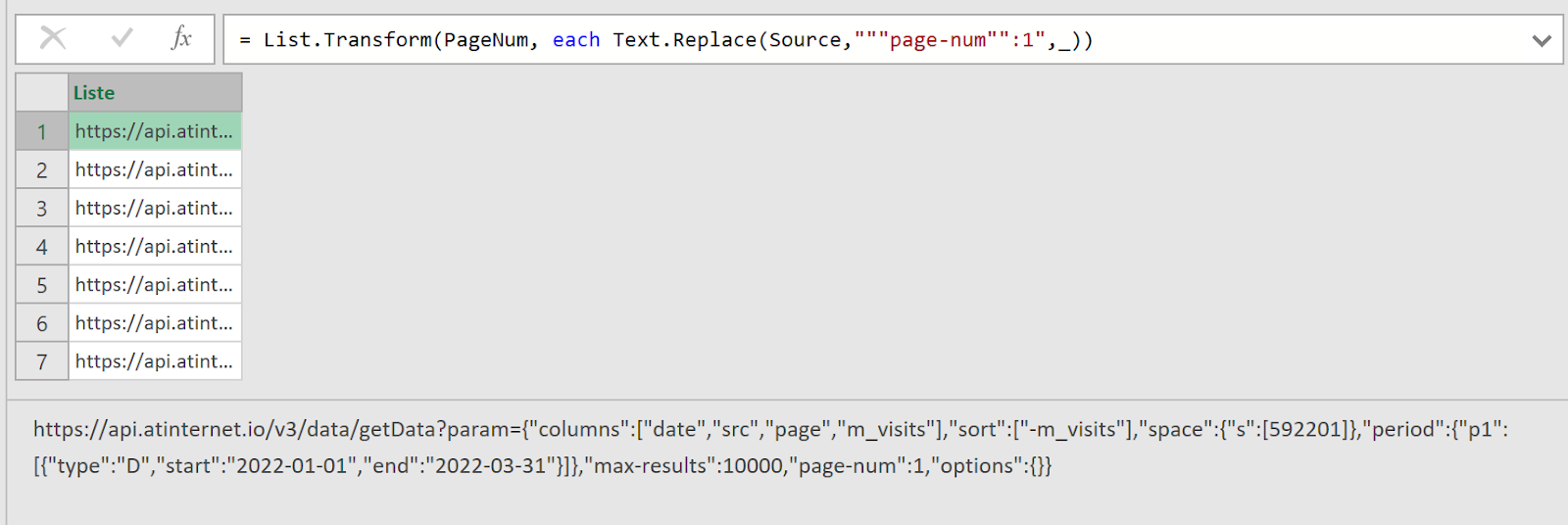
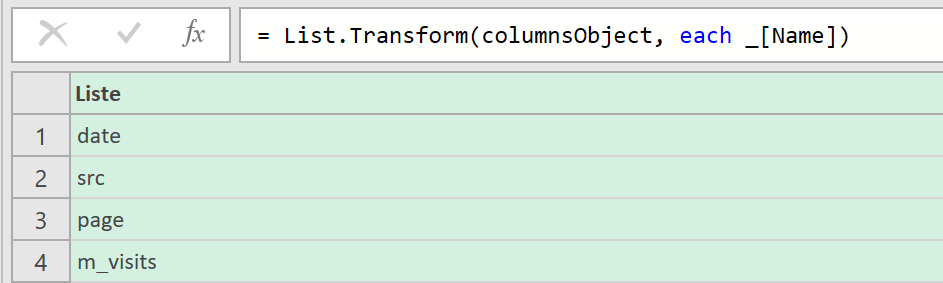
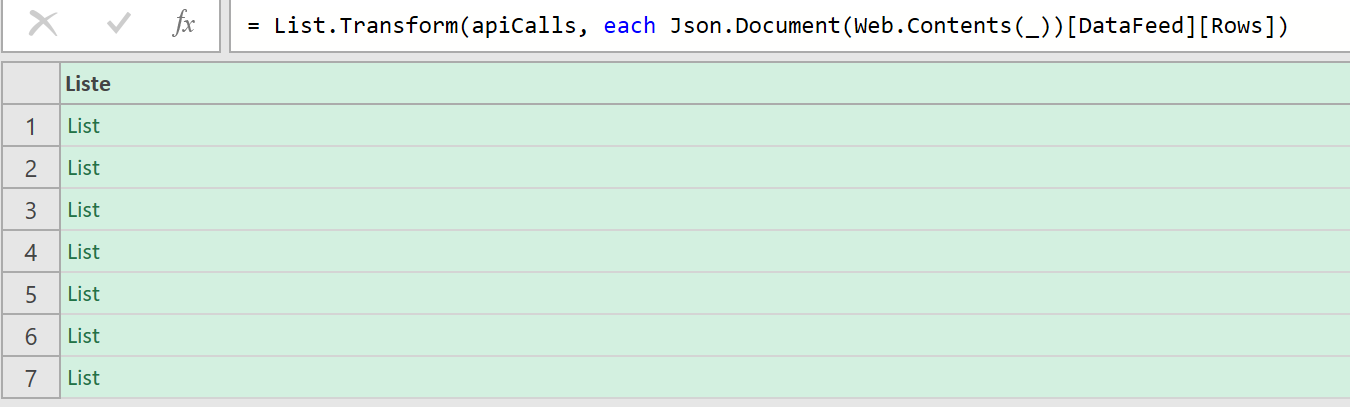
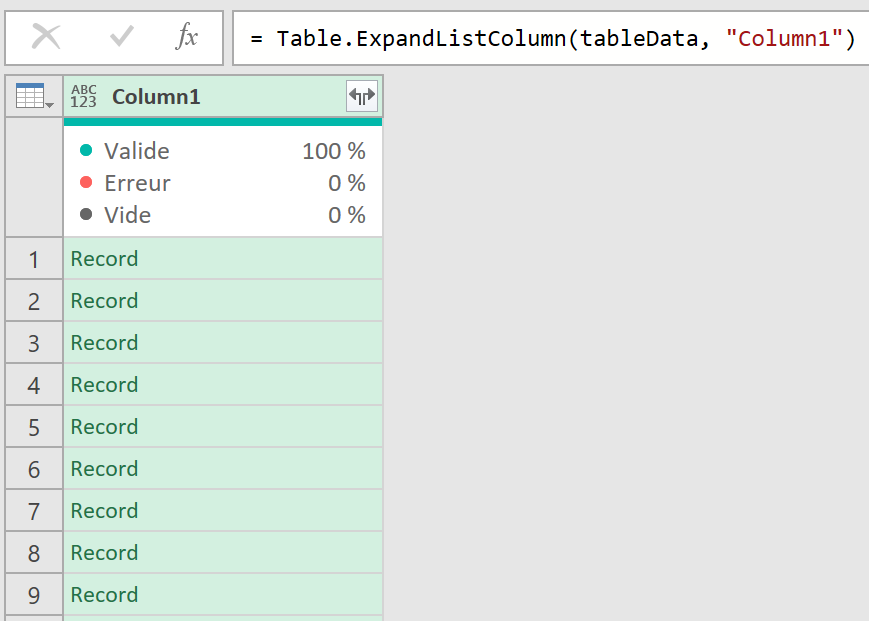
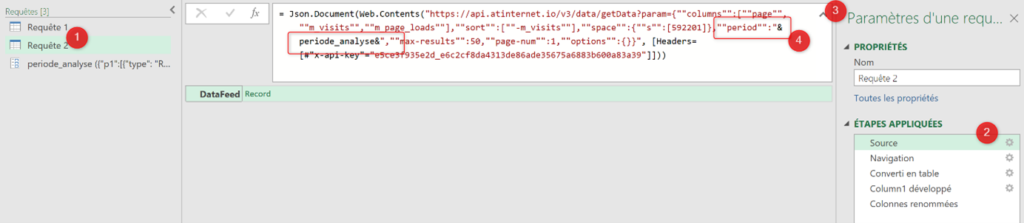
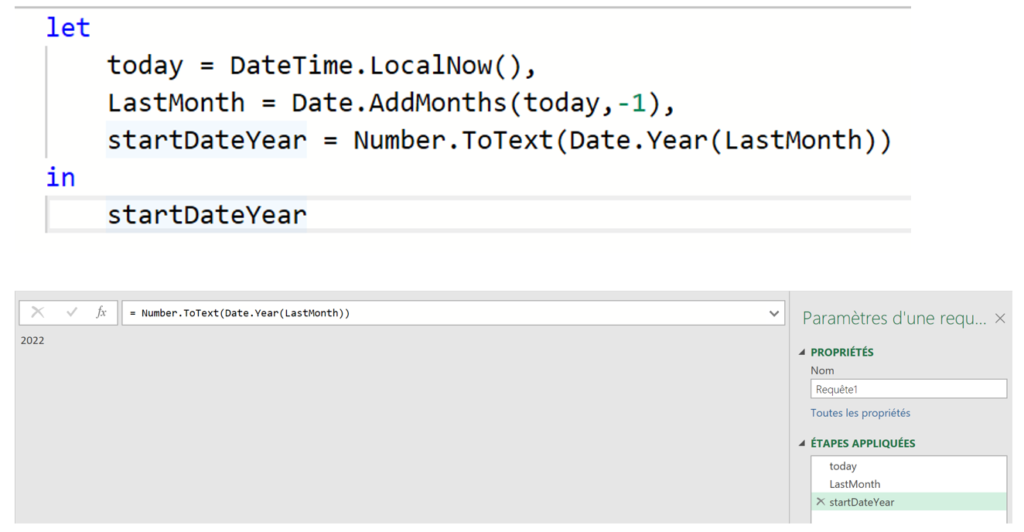
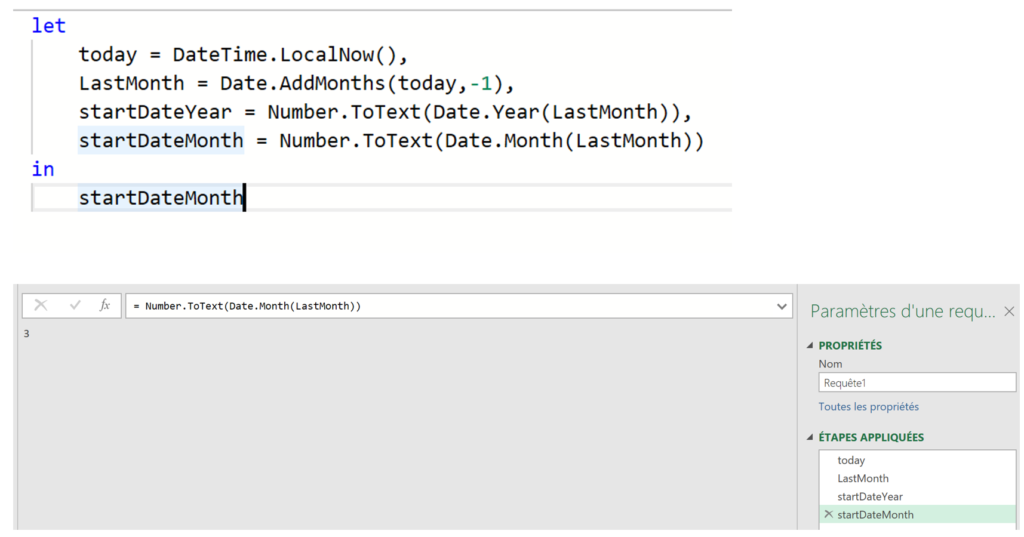
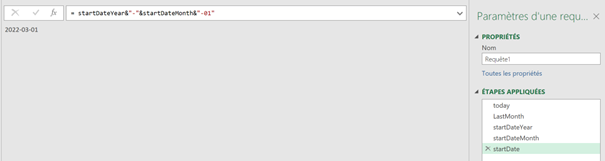
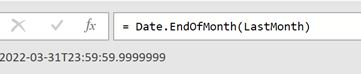
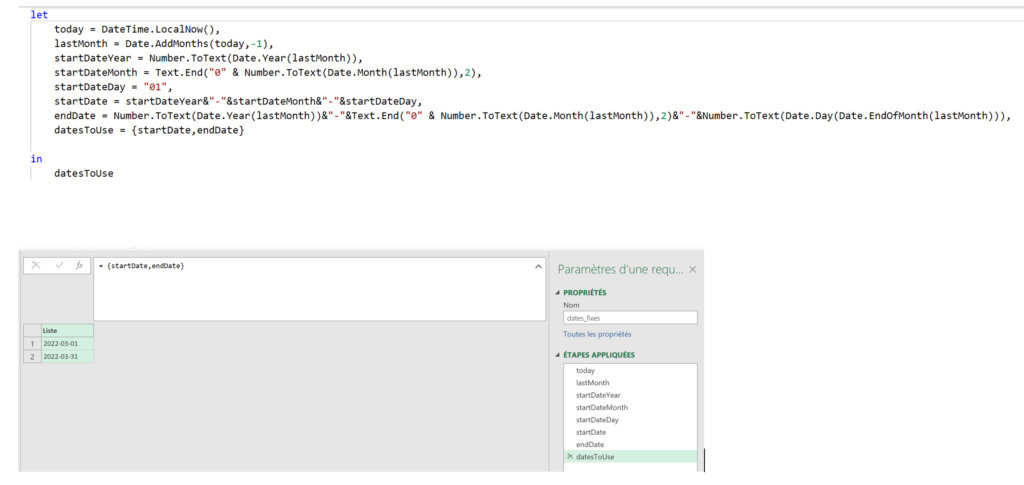
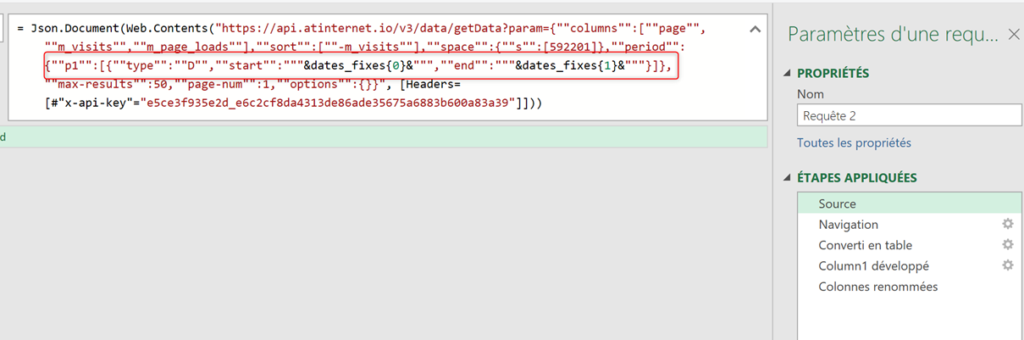
J’ai régulièrement à analyser des données de navigation à l’aide du module d’exploration de Piano Analytics. Toutefois, il est parfois compliqué d’extraire ces données pour les retravailler dans Excel ou les présenter dans PowerPoint.
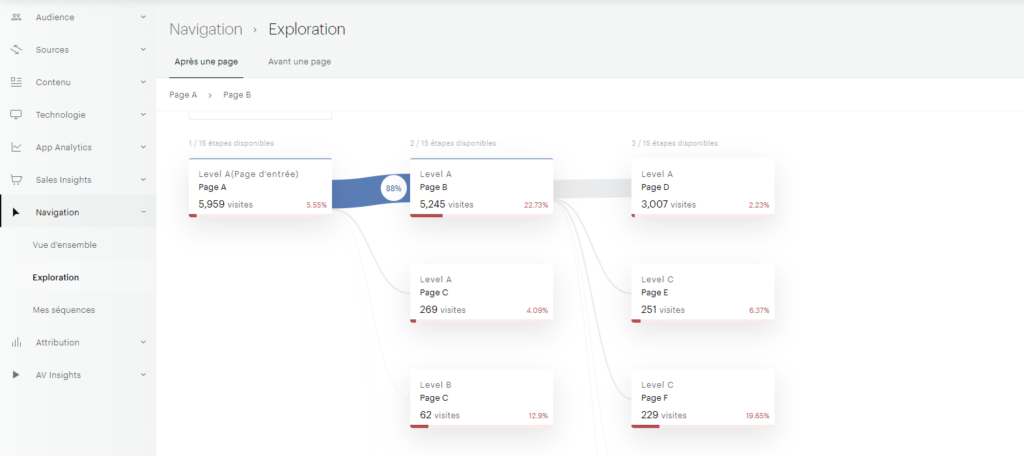
Explication sur le contenu de l’extract
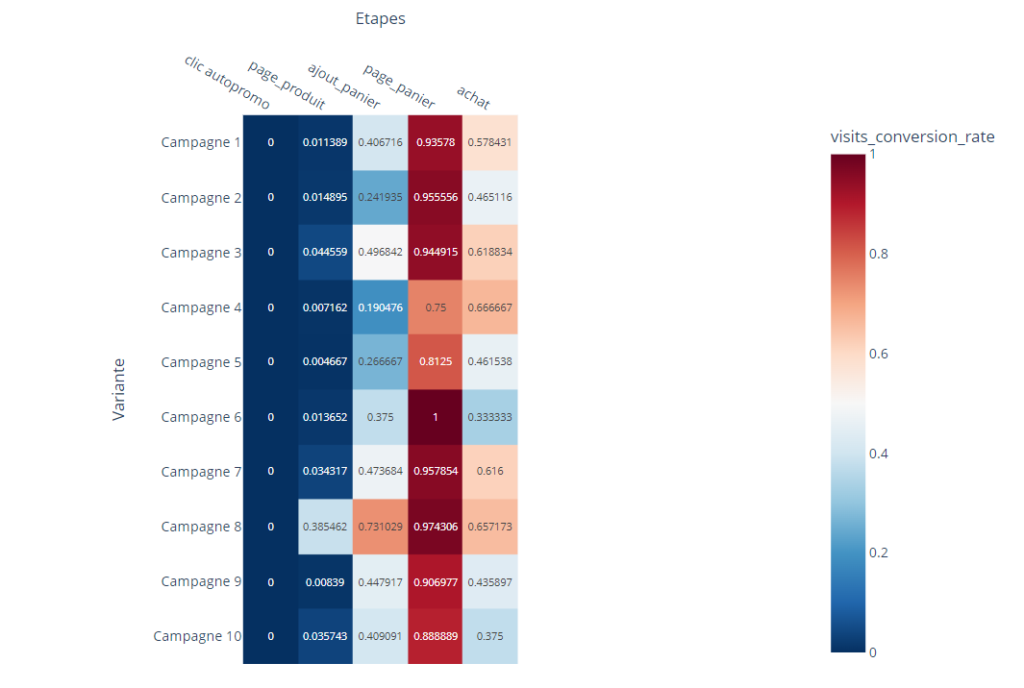
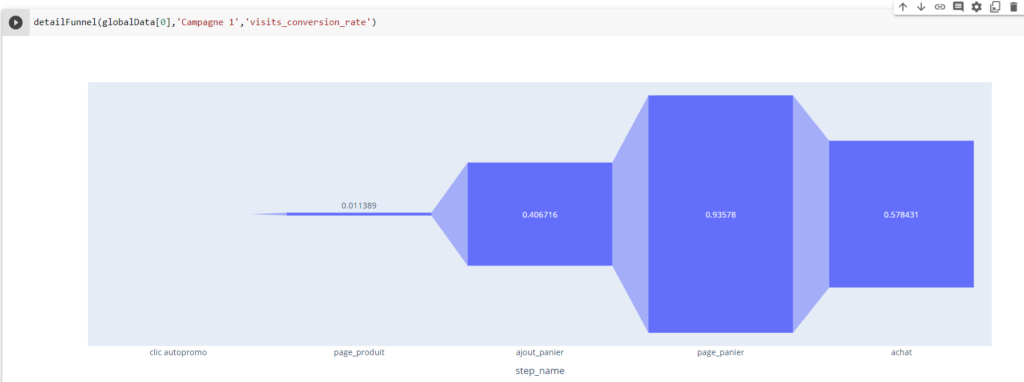
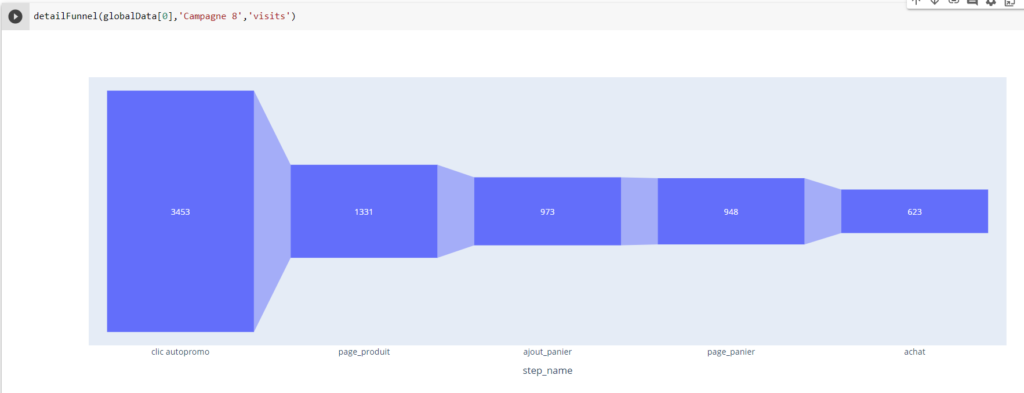
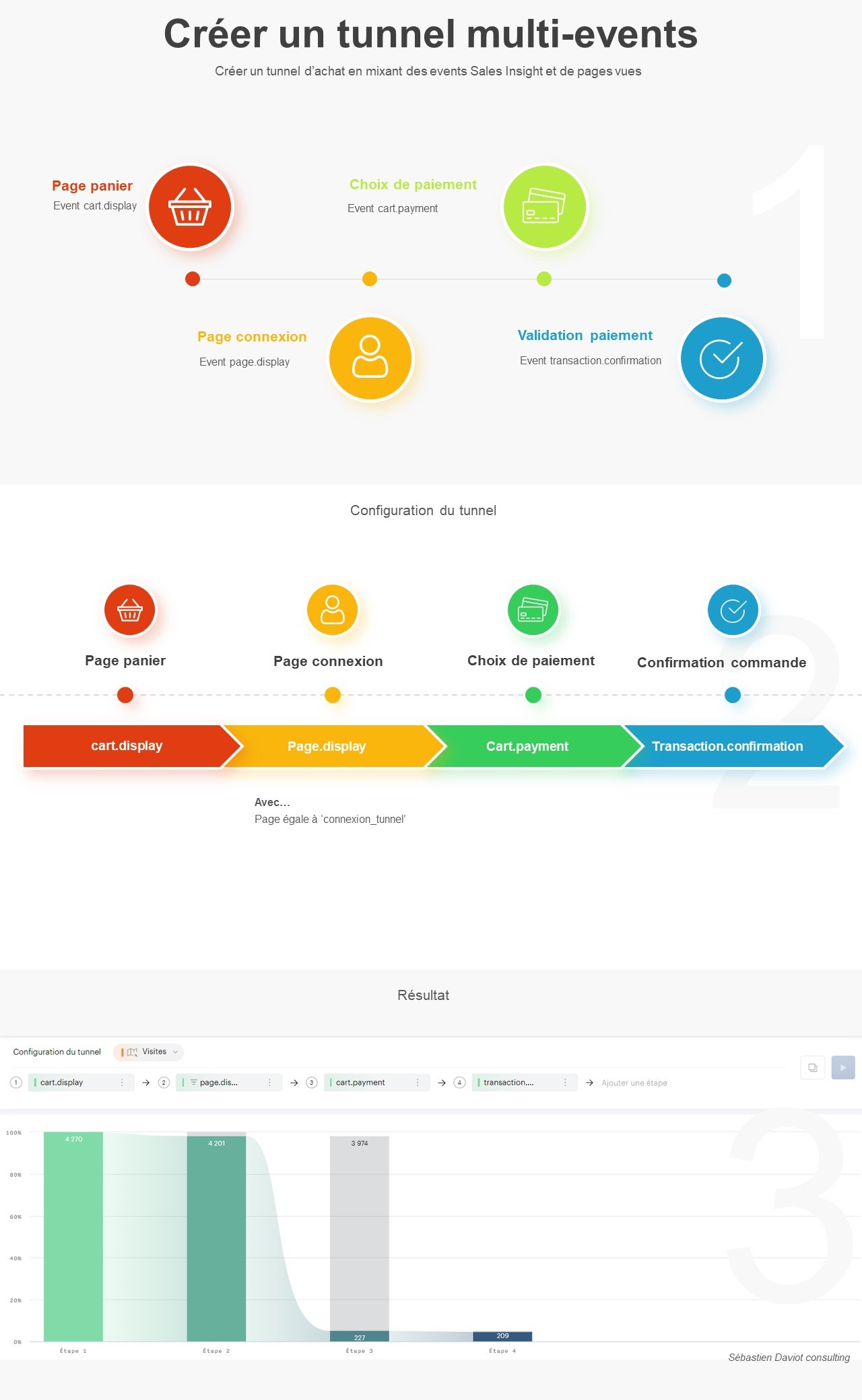
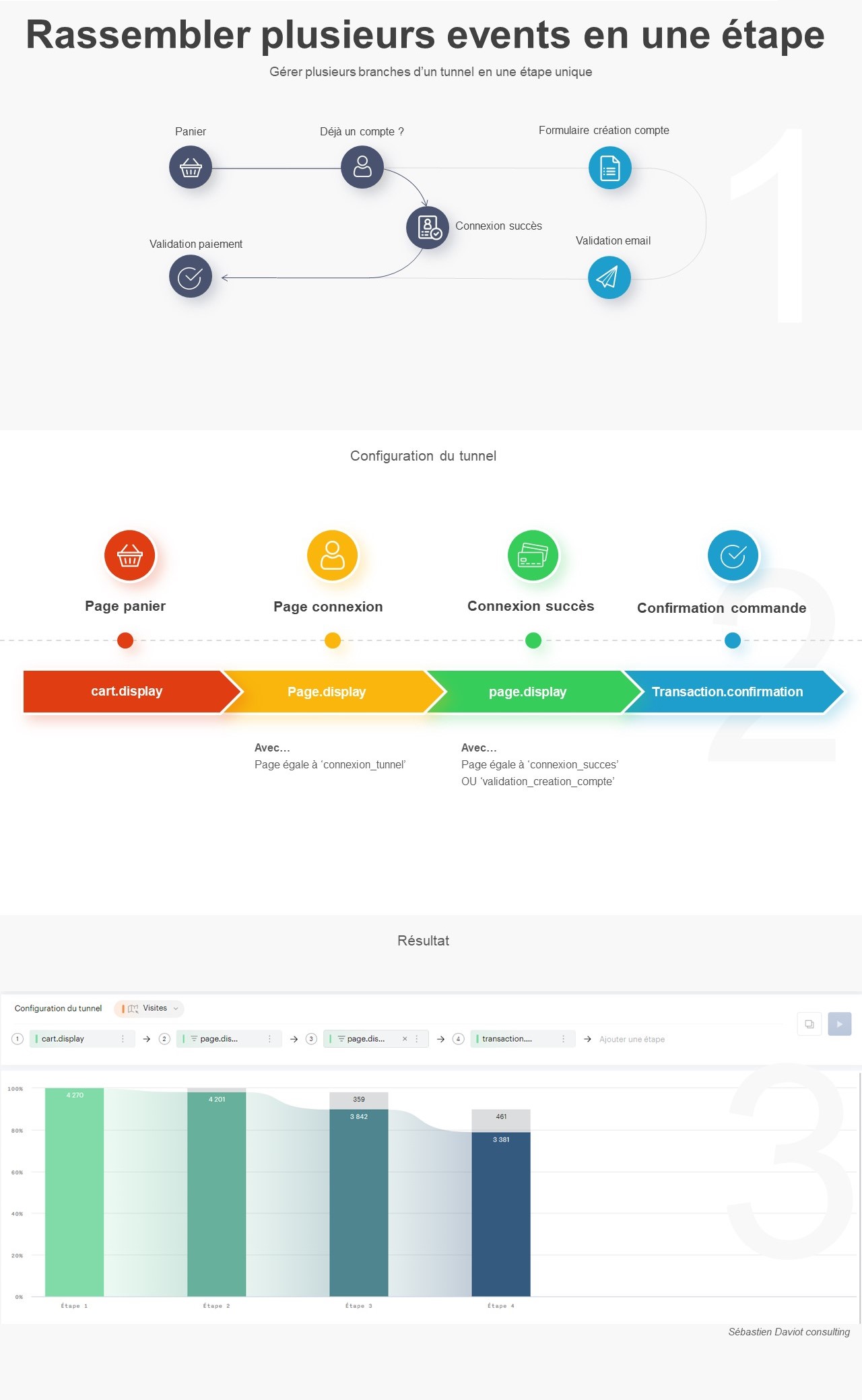
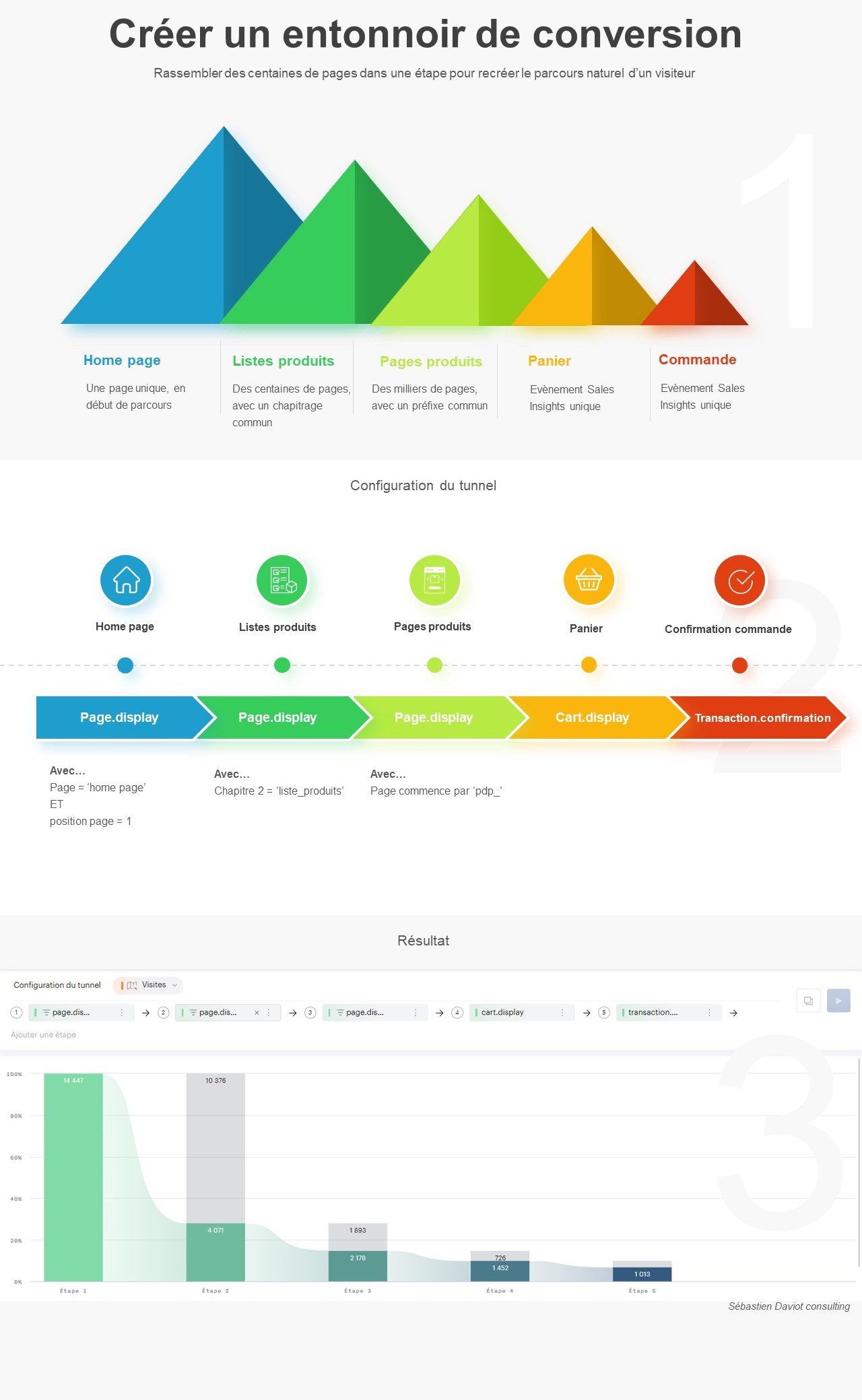
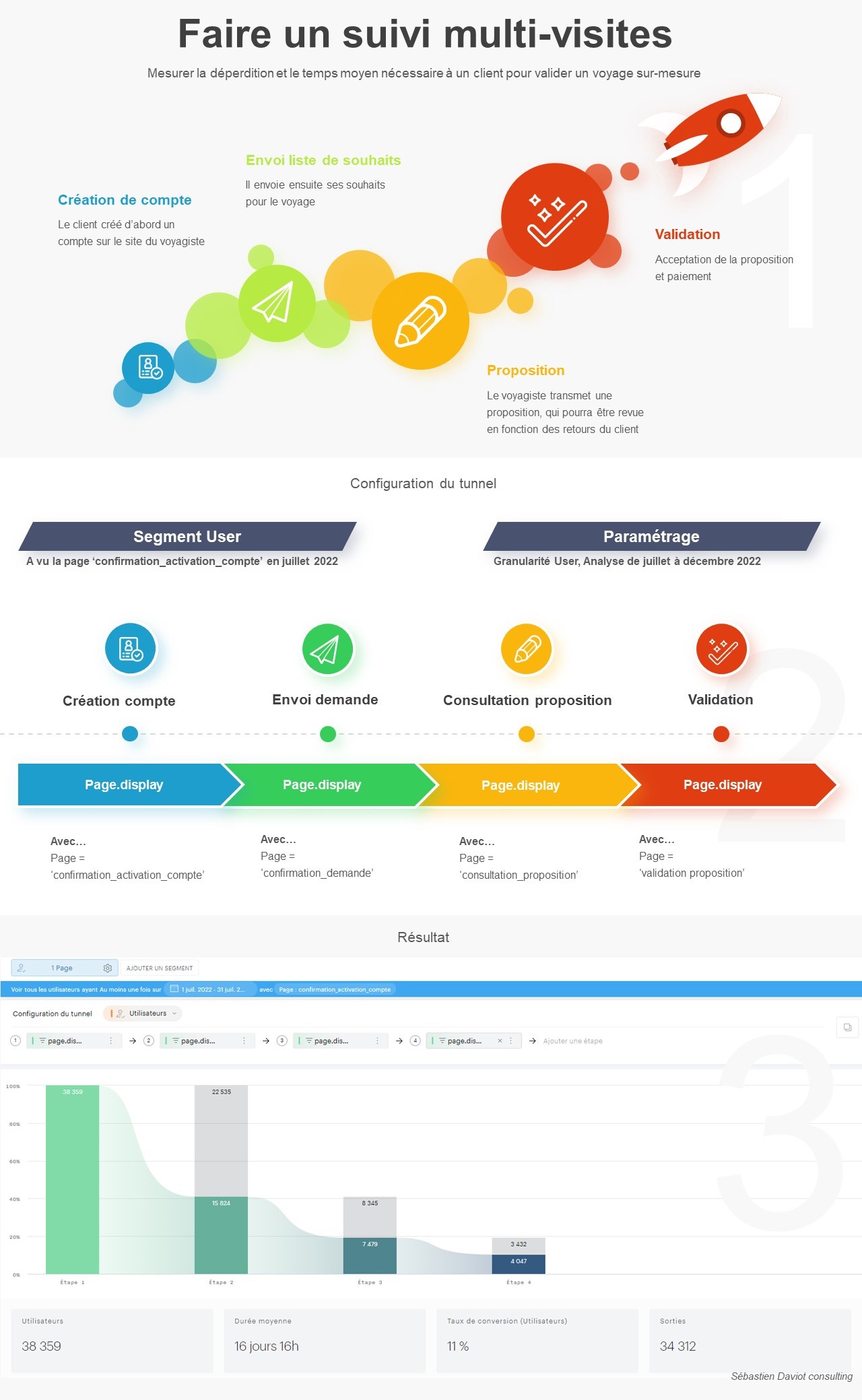
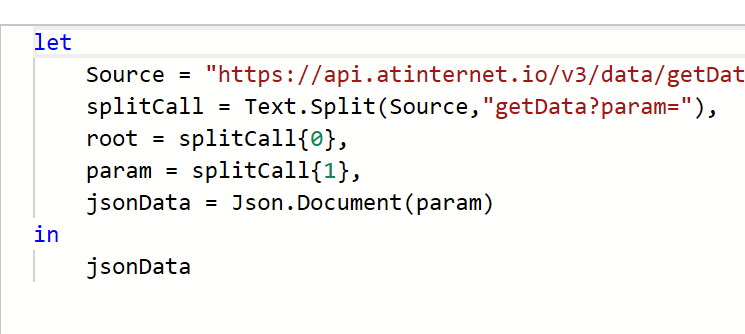
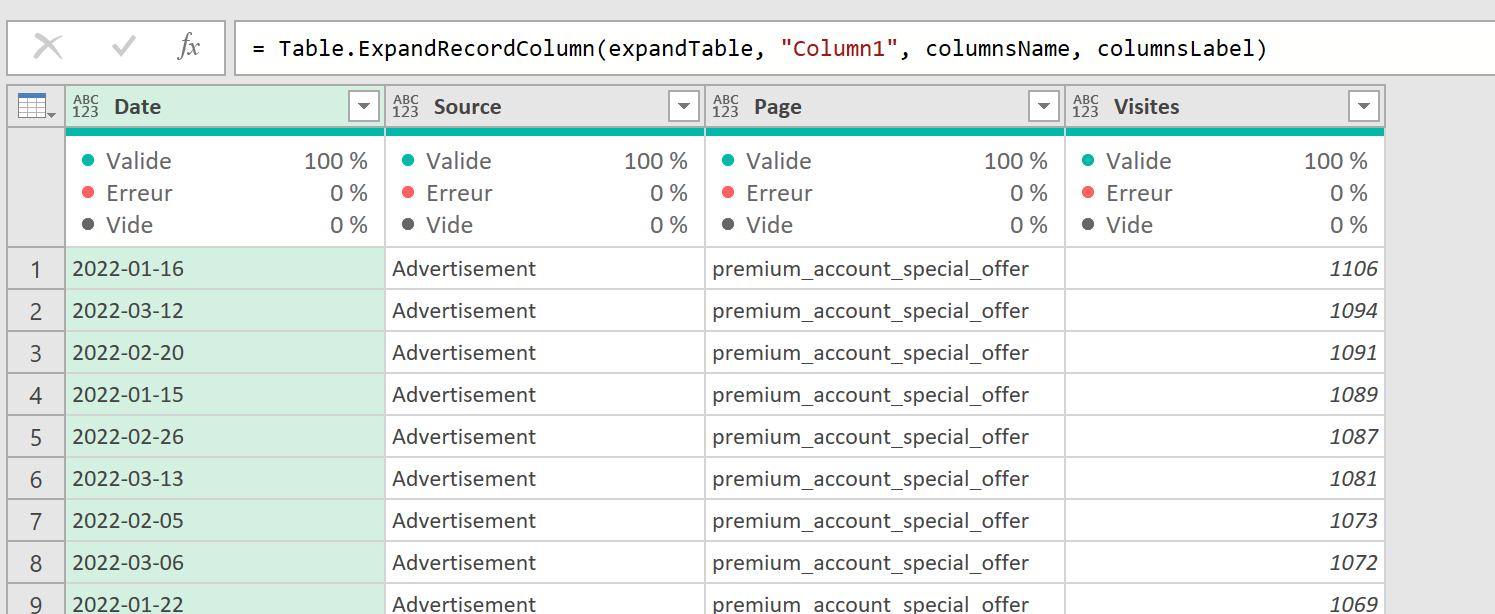
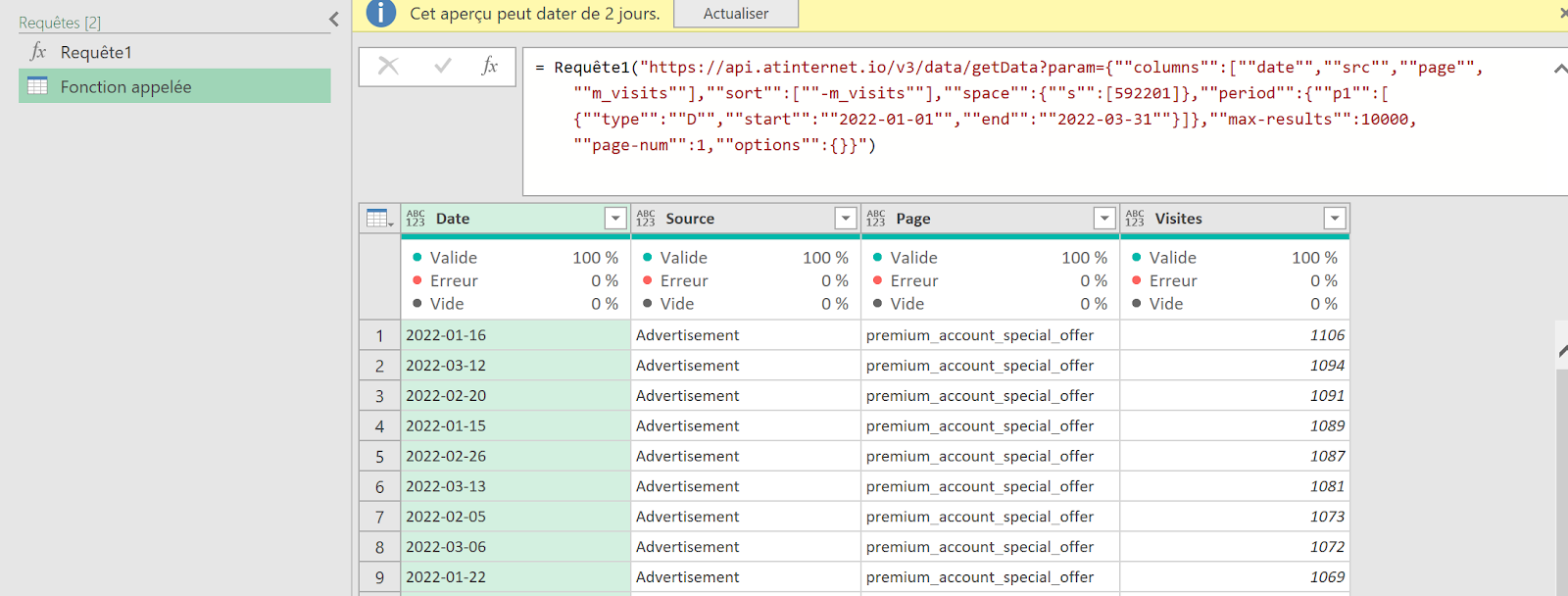
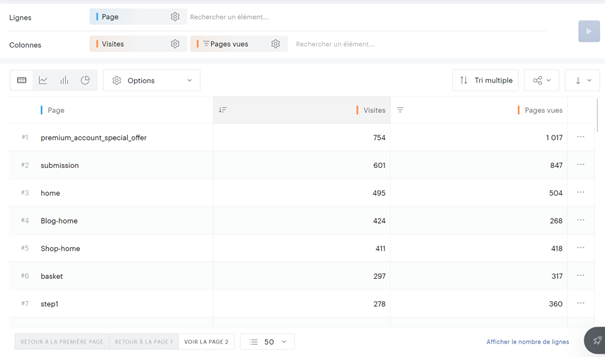
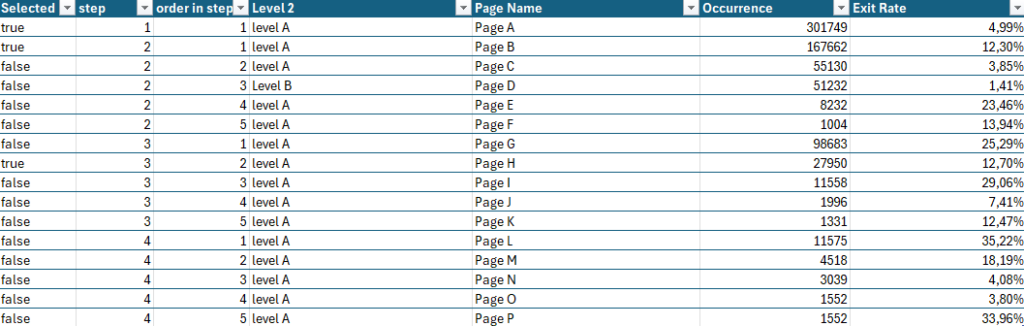
Pour faciliter ce processus, j’ai développé un petit code JavaScript permettant d’extraire l’ensemble des données de navigation affichées dans l’explorateur Piano. Ce script génère un fichier CSV contenant, pour chaque page, les informations suivantes :
- Si la page est sélectionnée dans le chemin de navigation en cours
- L’étape à laquelle appartient la page
- La position de la page dans l’étape (triée en fonction du volume)
- Le niveau 2 associé
- Le nom de la page
- Le nombre d’occurrences
- Le taux de sortie (uniquement disponible dans l’analyse exploratoire « après une page »)
Attention : Si vous effectuez une extraction en mode concentration (« avant une page »), les numéros d’étapes sont inversés (1 pour la dernière étape, 2 pour l’avant-dernière étape, etc.).
Utilisation du code
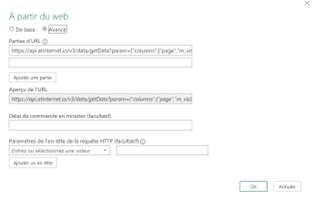
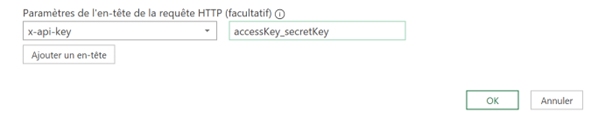
Le script JavaScript lit le DOM de la page pour récupérer les informations nécessaires et générer un fichier CSV. Pour l’utiliser, vous avez deux options.
- Ajouter le code en favori dans votre navigateur : Suivez les instructions ici pour installer un bookmarklet JavaScript, puis cliquez dessus lorsque vous êtes dans l’analyse de navigation
javascript:(function(){function extractDataAndExportToCSV(){const url=window.location.href;if(url.includes("https://analytics.piano.io/explorer/#/treeview/")){const stickers=document.querySelectorAll('.ats-treeview-container .treeview-sticker');const data=[];stickers.forEach(sticker=>{const isSelected=sticker.classList.contains('sticker-selected');const classList=Array.from(sticker.classList);const positionClass=classList.find(cls=>cls.startsWith('treeview-sticker-'));const x=parseInt(positionClass.split('-')[2]);const y=parseInt(positionClass.split('-')[3]);const level2=sticker.querySelector('.ats-b-treeview-sticker-subtitle')?.innerText||'';const pageName=sticker.querySelector('.ats-b-treeview-sticker-title')?.innerText||'';const occurrence=(sticker.querySelector('.ats-b-treeview-sticker-value')?.innerText||'').replace(/[\s,]/g,'');let exitRate=null;if(url.includes('/afterapage/')){const progressBarValue=sticker.querySelector('.ats-progress-bar-value')?.innerText||'';if(progressBarValue){exitRate=parseFloat(progressBarValue.replace('%','').replace(',','.'))/100;if(navigator.language==='fr-FR'){exitRate=exitRate.toString().replace('.',',');}}}data.push({Selected:isSelected,step:x+1,'order in step':y+1,'Level 2':level2,'Page Name':pageName,Occurrence:occurrence,'Exit Rate':exitRate});});const csv=convertToCSV(data);downloadCSV(csv);}}function convertToCSV(data){const header=Object.keys(data[0]).join(';');const rows=data.map(row=>Object.values(row).join(';'));return[header,...rows].join('\n');}function downloadCSV(csv){const blob=new Blob([csv],{type:'text/csv;charset=utf-8;'});const link=document.createElement("a");const url=URL.createObjectURL(blob);link.setAttribute("href",url);link.setAttribute("download","export.csv");link.style.visibility='hidden';document.body.appendChild(link);link.click();document.body.removeChild(link);}extractDataAndExportToCSV();})();- Exécuter le code suivant directement dans la console de votre navigateur
function extractDataAndExportToCSV() {
const url = window.location.href;
if (url.includes("https://analytics.piano.io/explorer/#/treeview/")) {
const stickers = document.querySelectorAll('.ats-treeview-container .treeview-sticker');
const data = [];
stickers.forEach(sticker => {
const isSelected = sticker.classList.contains('sticker-selected');
const classList = Array.from(sticker.classList);
const positionClass = classList.find(cls => cls.startsWith('treeview-sticker-'));
const x = parseInt(positionClass.split('-')[2]);
const y = parseInt(positionClass.split('-')[3]);
const level2 = sticker.querySelector('.ats-b-treeview-sticker-subtitle')?.innerText || '';
const pageName = sticker.querySelector('.ats-b-treeview-sticker-title')?.innerText || '';
const occurrence = (sticker.querySelector('.ats-b-treeview-sticker-value')?.innerText || '').replace(/[\s,]/g, '');
let exitRate = null;
if (url.includes('/afterapage/')) {
const progressBarValue = sticker.querySelector('.ats-progress-bar-value')?.innerText || '';
if (progressBarValue) {
exitRate = parseFloat(progressBarValue.replace('%', '').replace(',', '.')) / 100;
if (navigator.language === 'fr-FR') {
exitRate = exitRate.toString().replace('.', ',');
}
}
}
data.push({
Selected: isSelected,
step: x + 1,
'order in step': y + 1,
'Level 2': level2,
'Page Name': pageName,
Occurrence: occurrence,
'Exit Rate': exitRate
});
});
const csv = convertToCSV(data);
downloadCSV(csv);
}
}
function convertToCSV(data) {
const header = Object.keys(data[0]).join(';');
const rows = data.map(row => Object.values(row).join(';'));
return [header, ...rows].join('\n');
}
function downloadCSV(csv) {
const blob = new Blob([csv], { type: 'text/csv;charset=utf-8;' });
const link = document.createElement("a");
const url = URL.createObjectURL(blob);
link.setAttribute("href", url);
link.setAttribute("download", "export.csv");
link.style.visibility = 'hidden';
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
}
extractDataAndExportToCSV();Conseils d’exploitation dans Excel
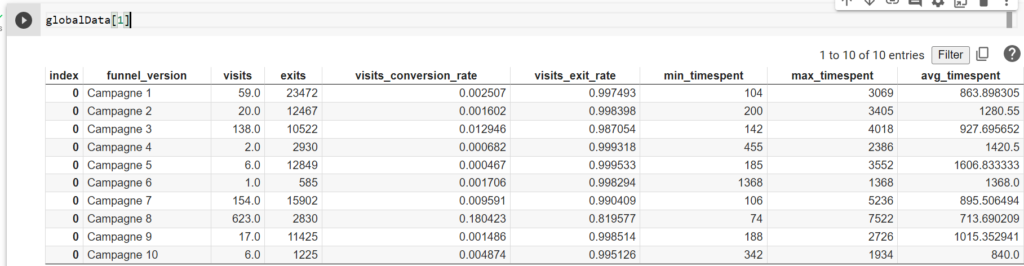
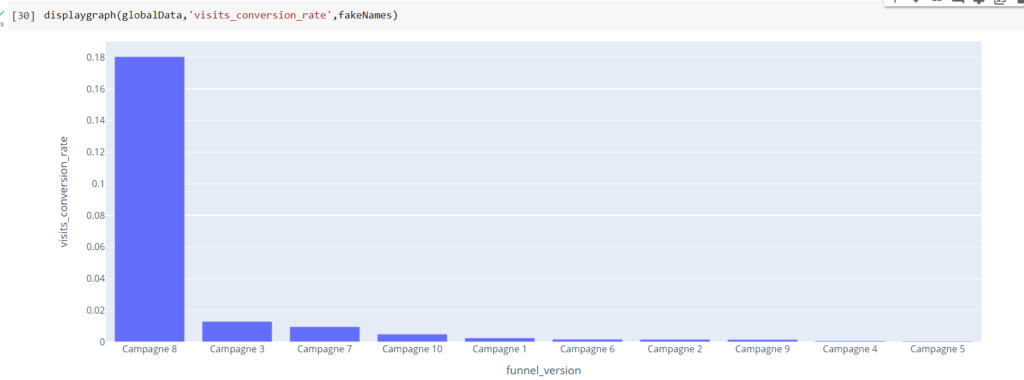
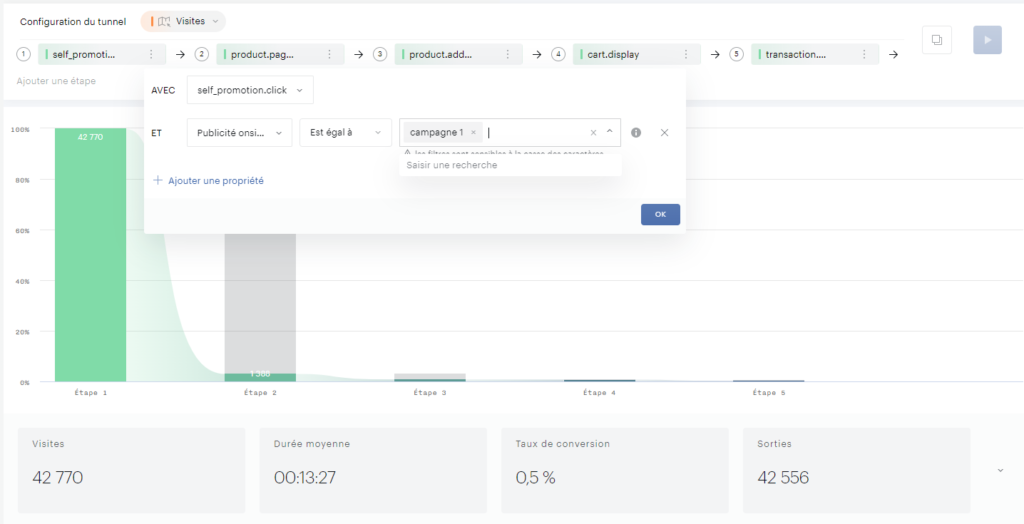
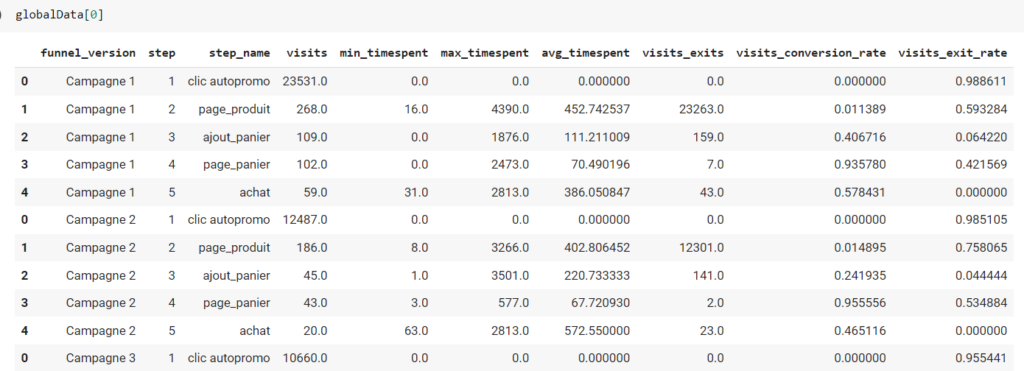
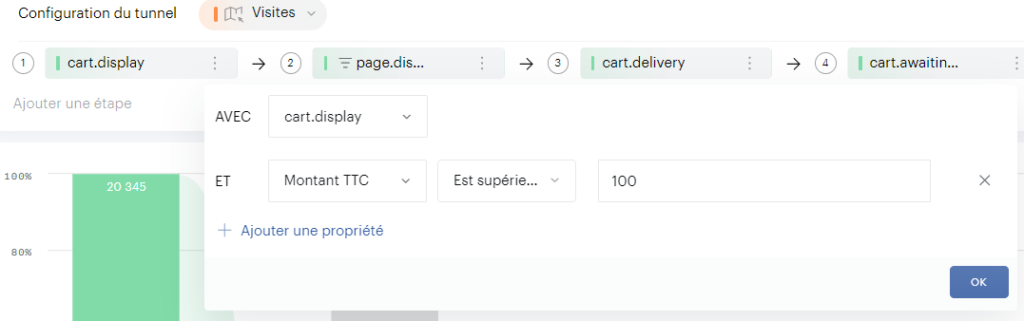
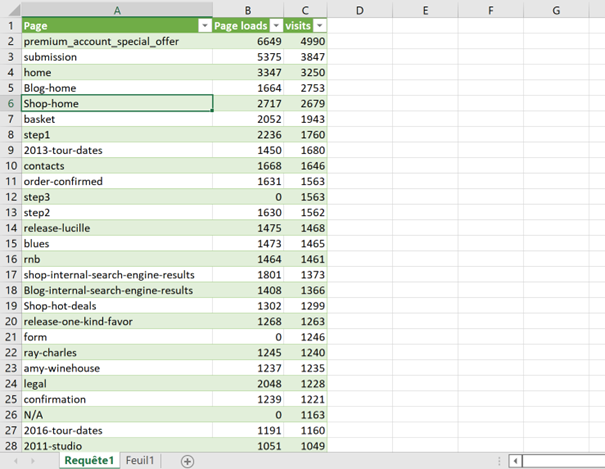
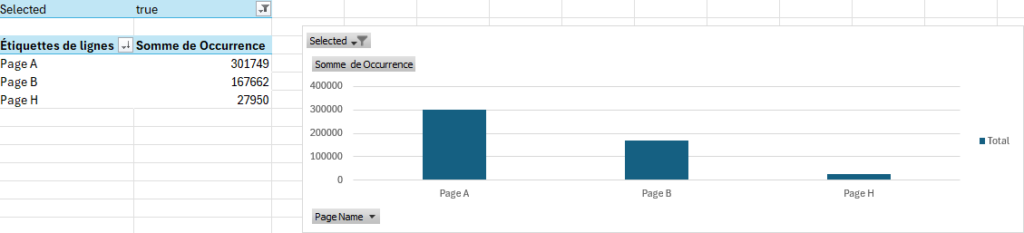
Pour recréer le tunnel sélectionné dans Piano, vous pouvez filtrer les données dans Excel en utilisant la colonne « Selected » = True :
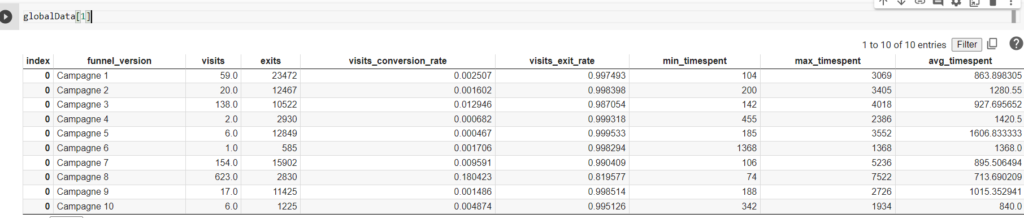
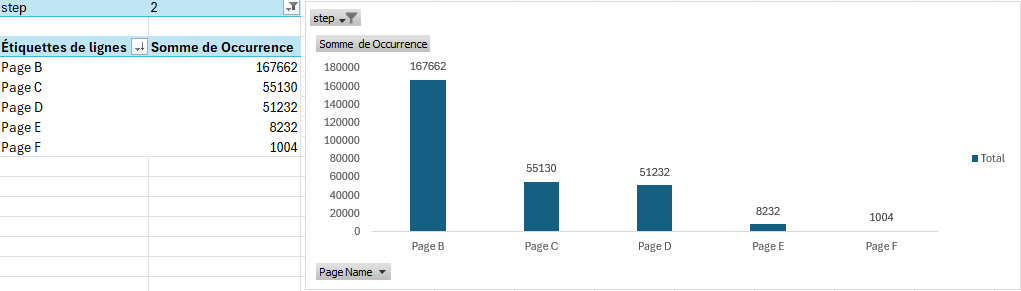
Si vous souhaitez obtenir la distribution des pages pour une étape précise, il suffit de filtrer sur le numéro d’étape :
Note importante : Ce code se base sur la structure actuelle de la page de Piano Analytics et pourrait ne plus fonctionner en cas de modification de celle-ci. Je ferai de mon mieux pour maintenir le script à jour, mais n’hésitez pas à me signaler tout dysfonctionnement.