
Bienvenue dans ce nouveau guide pratique visant à transformer des données brutes provenant des avis Apple Store et Google play Store en informations stratégiques exploitables dans un dashboard, le tout en Python !
Mon objectif dans cette vidéo est de vous montrer comment exploiter concrètement l’IA via Python pour extraire des données qualitatives non structurées. Ces données sont ensuite transformées en tableaux de bord exploitables (utilisant Streamlit et Plotly) et enrichies par des analyses générées par un LLM (Gemini). Le tout s’accompagne d’une exploration des aspects techniques nécessaires, notamment la récupération de données via des API ou des outils de scraping.
Ce projet ne se veut pas une fin en soi, mais un point de départ pour de nombreux cas d’usage avancés.
Sommaire
La Logique Globale du Projet
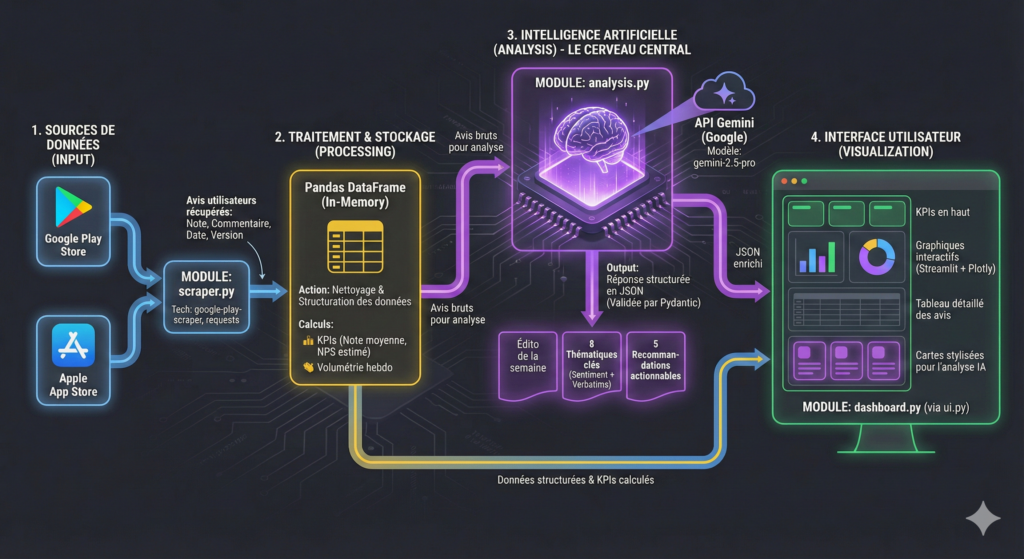
Le flux de travail du projet repose sur la mise en place d’une chaîne de traitement des données en trois étapes clés :
1. Récupération des avis : L’approche consiste à aller chercher les avis déposés sur les plateformes (comme le Google Play Store et l’Apple Store, en utilisant l’exemple de l’application Mistral) via des librairies de scraping spécifiques et des flux RSS.
2. Préparation et Analyse Statistique : Les données, souvent de formats différents entre les stores, sont uniformisées, nettoyées et structurées à l’aide de la librairie Pandas (l’équivalent d’un « Excel de Python »). C’est là que sont calculés les indicateurs statistiques de base (note moyenne, répartition des notes, volumes, promoteurs/détracteurs).
3. Enrichissement par l’IA et Dashboarding : Les données préparées sont soumises à l’API de Gemini (un LLM) pour en tirer des insights qualitatifs. Ces résultats, combinés aux statistiques traditionnelles, sont affichés dans un tableau de bord interactif créé avec Streamlit et des visualisations Plotly
Les Grandes Thématiques Abordées dans le Tutoriel

Le cours s’articule autour des principaux axes techniques suivants, qui constituent les chapitres fondamentaux du projet :
1. Extraction et Uniformisation des Données
Cette section aborde les défis de la récupération de données à partir de sources externes, qui nécessitent souvent des méthodes différentes.
• Scraping et API : Nous utilisons des librairies Python pour extraire les avis du Google Play Store et exploitons le flux RSS d’Apple App Store.
• Nettoyage et data framing : L’utilisation de Pandas est détaillée pour transformer les avis récupérés en DataFrames (tableaux) exploitables, assurant l’uniformisation des noms et du typage des colonnes entre les différentes sources.
2. Calcul des KPI et Visualisation
Au-delà de la simple récupération, il est crucial de fournir une analyse factuelle et visuelle des données.
• Indicateurs Clés de Performance (KPI) : Calcul de métriques essentielles, comme la note moyenne des avis, le volume total, et la segmentation des utilisateurs en promoteurs, neutres et détracteurs.
• Visualisations interactives : La librairie Plotly Express est utilisée pour générer des graphiques riches (comme des histogrammes ou des p charts) qui sont ensuite intégrés au dashboard, offrant une interactivité pour l’utilisateur final.
3. Exploitation de l’Intelligence Artificielle Générative
C’est la partie qui apporte la valeur ajoutée qualitative au dashboard, transformant des centaines d’avis en synthèses concises.
• Requêtes LLM structurées : Apprendre à interroger l’API de Gemini (2.5 Pro ou Flash) pour demander des analyses complexes d’un bloc de texte conséquent.
• Génération d’insights qualitatifs : L’IA est sollicitée pour produire trois types d’analyses clés : un éditorial résumant les événements de la semaine, les thématiques clés abordées dans les avis (avec un sentiment associé et une citation illustrative) et des recommandations actionnables pour les équipes produit ou marketing.
• Fiabilisation des Sorties (Pydantic) : Un élément technique indispensable en production est l’utilisation de Pydantic pour forcer le LLM à retourner un format de données JSON spécifique et immutable.
4. Construction du Dashboard (Streamlit)
Le dashboard sert de vitrine aux analyses.
• Mise en place avec Streamlit : Création d’une interface web simple mais efficace pour afficher les KPI, les graphiques Plotly et les insights IA.
• HTML/CSS Dynamique : Utilisation de l’injection HTML et CSS dynamique pour affiner la mise en forme des résultats générés par l’IA (par exemple, afficher un liseré vert pour un sentiment positif ou rouge pour un négatif).
Vers l’Industrialisation du Projet
Ce tutoriel est une base solide, mais pour une utilisation réelle en entreprise, plusieurs pistes d’amélioration sont à considérer :
• Déploiement et Scalabilité : Le code est développé en local, mais il devrait être déployé sur un serveur (via un service cloud comme AWS, Azure ou GCP) pour garantir la robustesse, la sécurité et la possibilité de mise à l’échelle.
• Historisation des Données : Pour un suivi dans le temps, il serait nécessaire de ne pas écraser les données à chaque exécution, mais de les stocker dans une base de données (plutôt que dans un simple fichier CSV) pour analyser l’évolution des notes moyennes ou des thématiques sur plusieurs mois.
• Distribution Automatisée : Mettre en place un système d’automatisation (scheduler) pour exécuter le script quotidiennement ou hebdomadairement, et potentiellement distribuer les résultats (par e-mail ou intégration dans d’autres outils de BI, comme Looker Studio ou Power BI).
Ce projet vous équipe des compétences nécessaires en Python, Data Analyse et IA pour aborder des problématiques de plus en plus complexes.